2025
MetaCentrum v číslech 2025

Počet uživatelů
Na konci roku 2025 mělo MetaCentrum 4 621 aktivních uživatelů. Ve srovnání s koncem roku 2023 (3 490 účtů) jde o nárůst o 32 %. Tento trend potvrzuje, že zájem o akademické výpočetní zdroje v ČR neustále stoupá.
Výpočetní kapacity
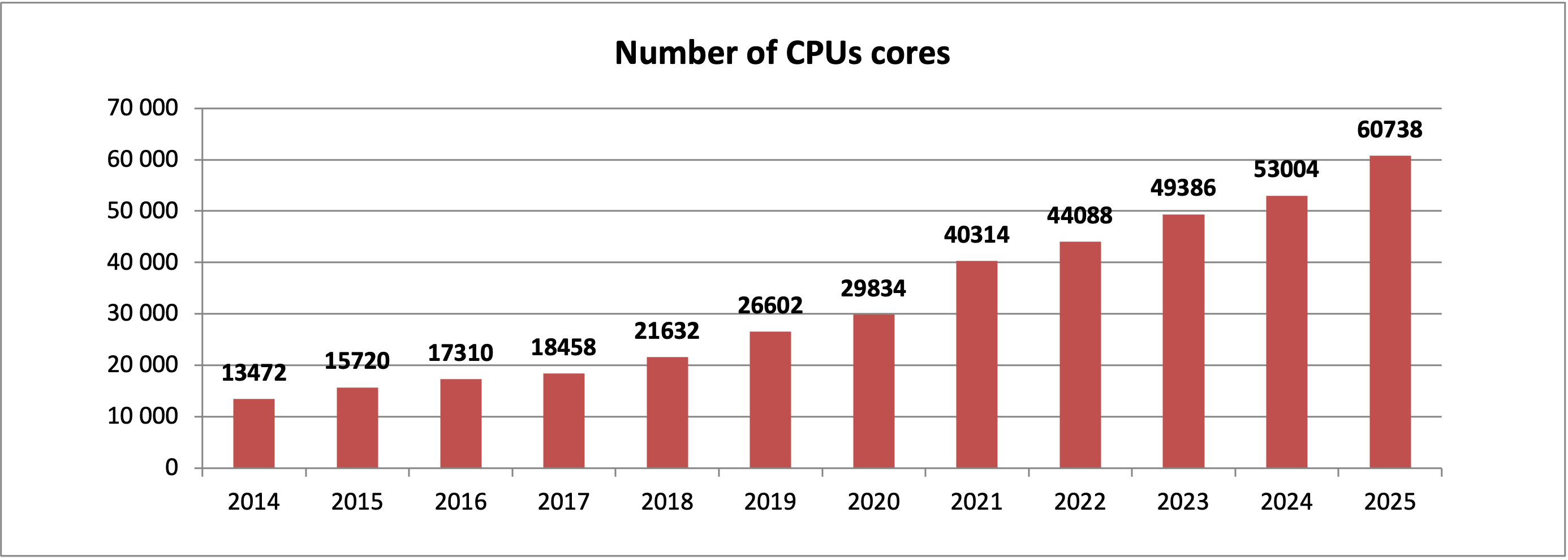
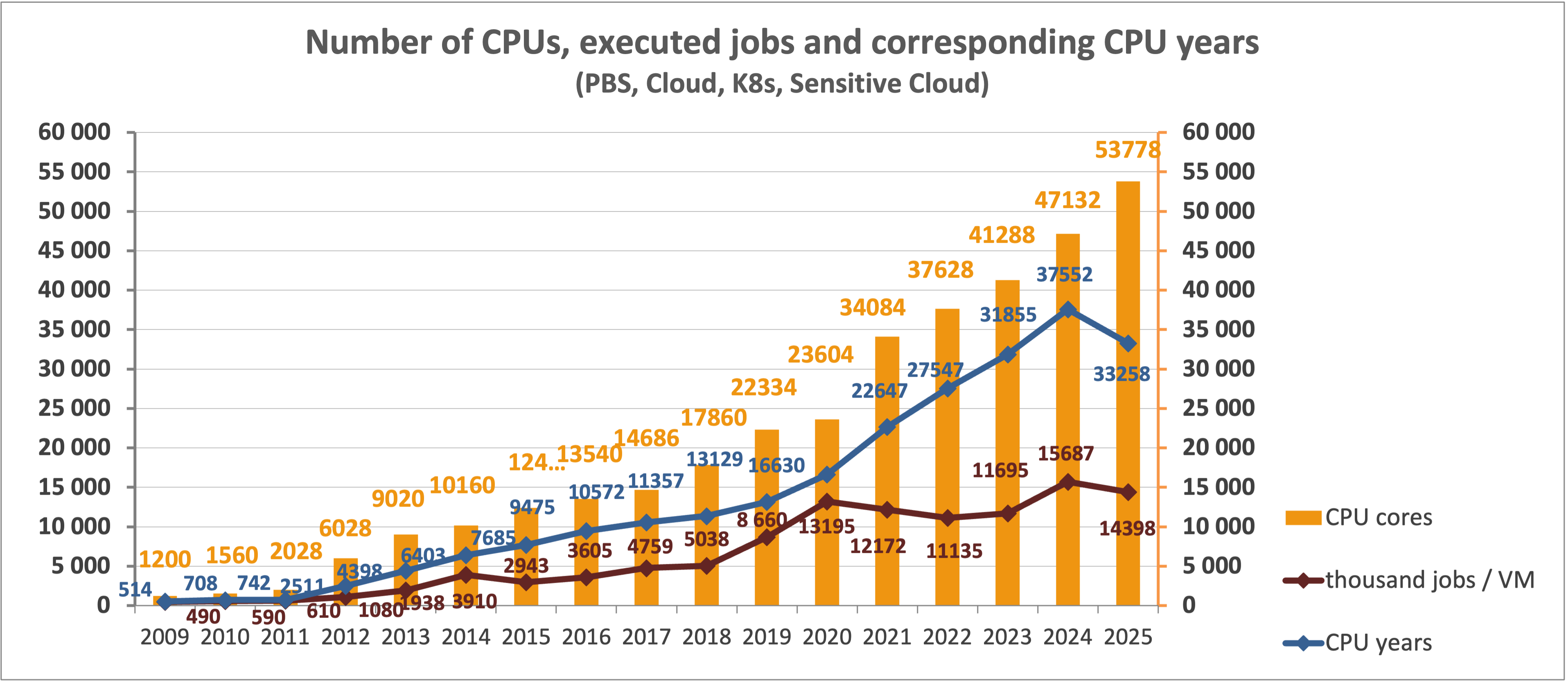
Celkový počet dostupných CPU jader v národním prostředí (včetně zapojení do mezinárodní sítě EGI) dosáhl 60 738 (pro srovnání 53 004 v roce 2024).
Vývoj počtu dostupných CPU jader v MetaCentru v průběhu let:
Propočítaný výpočetní čas
Uživatelé MetaVO v roce 2025 propočítali celkem 33 258 CPU let a 384 GPU let.
Detailní rozdělení podle jednotlivých prostředí:
- Dávkový systém (PBS): na 39 988 jádrech se propočítalo více než 25 tisíc CPU let v téměř 8 milionech úloh. Více než 500 tis. úloh vyžadovalo výpočetní akceleraci pomocí GPU. Na 5 984 CPU jádrech projektu ELIXIR se propočítalo 1 214 CPU let. Podrobnější statistiky zde.
- MetaCentrum Cloud: k dispozici na konci roku bylo 9 670 CPU jader, propočítalo se na nich celkem 4,2 tis. CPU let na téměř 81 tisících virtuálních strojů. Podrobnější statistiky zde.
- Kubernetes: v provozu 3 008 CPU jader (a 47 GPU karet), které popočítaly 1 760 CPU let v 6,42 milionech podů. Podrobnější statistiky zde.
- SensitiveCloud: dedikované prostředí pro citlivá data s 1 112 CPU jádry (40 GPU), propočítáno 657 CPU let v 38 tisících podech. Část grafické kapacity byla dedikována pro AI inferenci. Podrobnější statistiky zde.
- EGI: provozováno 6 960 CPU jader (HTC) a další proměnlivá část jader je exportována do FedCloudu z MetaCentrumCloudu. Výpočet propočítaného času se EGI řídí jinou metrikou než v národním měřítku, používá se tzv. HEPSCORE23. Podle tohoto skóre bylo propočítáno 5860 CPU let v HTC prostředí (ekvivalent naší PBS) a 41 CPU let (dle naší metriky) se propočítalo v našem MetaCentruCloudu. Podrobnější statistiky zde.
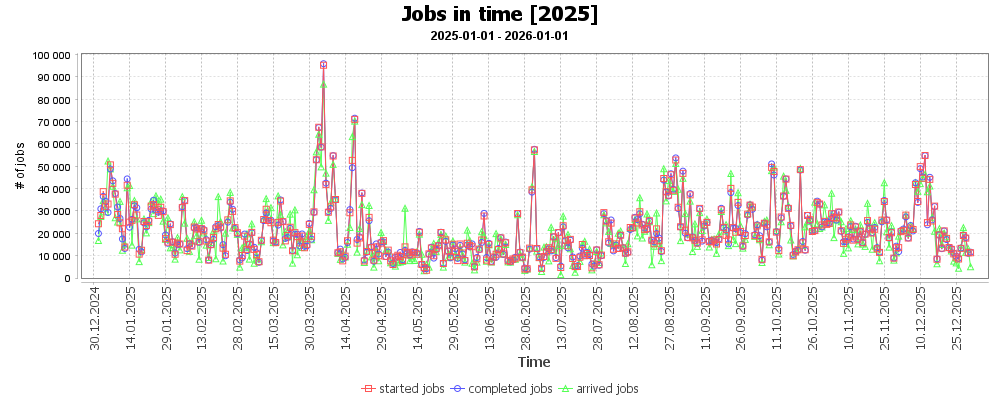
Statistiky ukazují, že zatímco počet dostupných CPU jader a celkový propočítaný čas (mimo statistiky EGI) rostly v uplynulých letech lineárně, počet úloh stagnuje a osciluje kolem 14 milionů ročně. Důvodem je vysoká režijní zátěž plánovače při zpracování velkého množství drobných požadavků, proto uživatelům doporučujeme sdružovat výpočty do objemnějších úloh.
V roce 2025 jsme zavedli limity na počet souběžně běžících úloh a maximální okamžité využití CPU jader jedním uživatelem. Tímto krokem se podařilo eliminovat negativní dopad tzv. „výplňových úloh“ (desítky tisíc krátkých výpočtů denně), což vedlo k mírnému poklesu celkového CPU času oproti loňsku. Současně sledujeme výrazný nárůst kapacity a využití GPU uzlů. Rostoucí trend úloh optimalizovaných pro GPU akcelerátory přirozeně vytlačuje část klasických CPU výpočtů.
Vlastníci výpočetních zdrojů
- 25 249 CPU jader patří sdružení CESNET.
- 9 625 CPU jader vlastní CERIT-SC.
- 25 864 CPU jader vlastní univerzity a ústavy AV ČR.
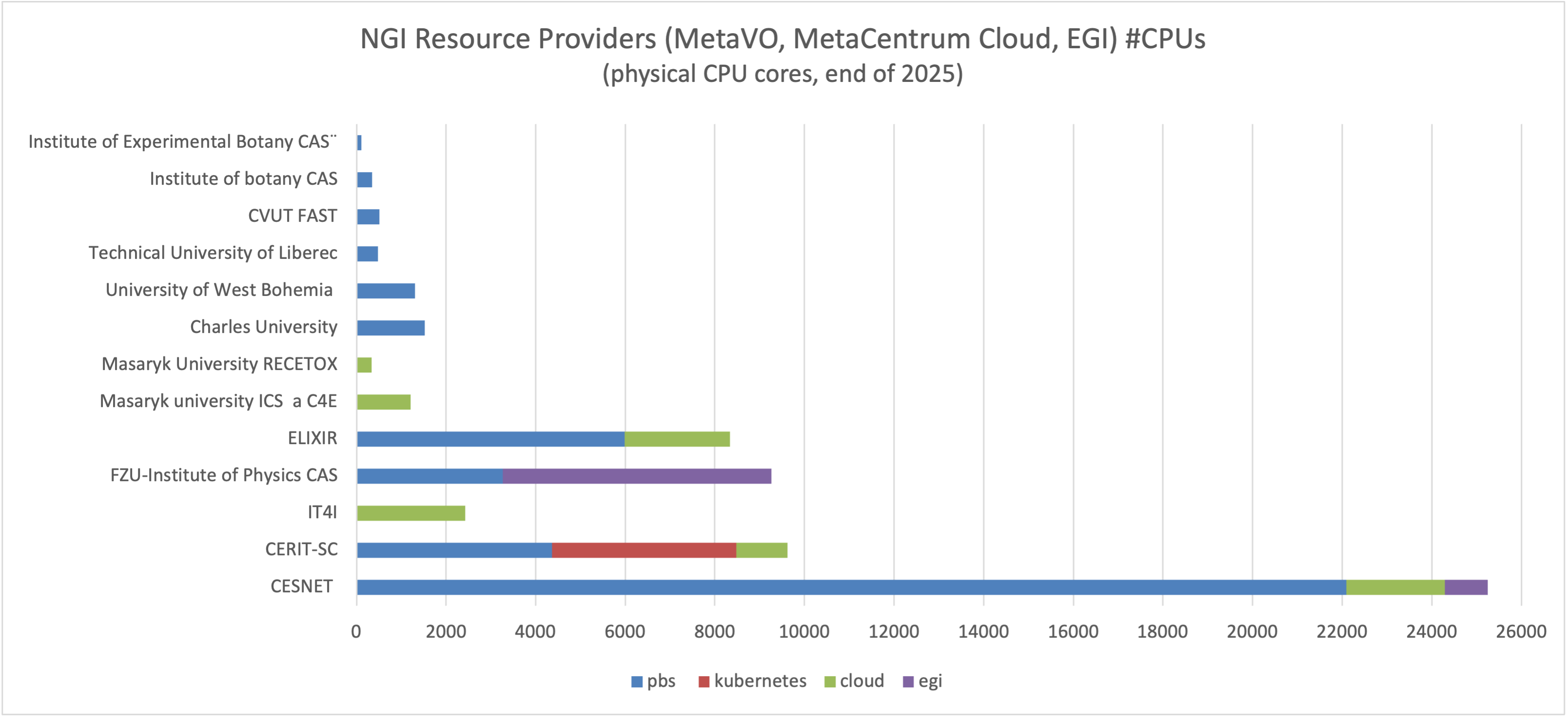
Na konci roku 2025 bylo v MetaCentru k dispozici celkem 60 738 CPU jader v následujícím členění dle vlastníků a služeb:
- CERIT-SC (9 625 CPU jader): bee, capy, uruk, ursa, glados, zia, zenon, kuba, kubah, kubas, eli; zapojené dle potřeby v PBS, K8s nebo v MetaCloudu/FedCloudu
- PBS (4 360 CPU jader)
- Kubernetes a SensitiveCloud (4 120 CPU jader)
- cloud (1 145 CPU jader)
- CESNET (25 249 CPU jader)
- PBS (22 092 CPU jader): aman, adan, tarkil, fobos, halmir, galdor, tyra, turin, grimbold, hildor
- MetaCloud (2 197 CPU jader): cloud
- EGI HTC (960 CPU jader): skurut
- ELIXIR (8 336 CPU jader)
- PBS (5 984 CPU jader): elbi, elmu, eluo, elum, elmo, elwe, eltu
- MetaCloud (2 352 CPU jader): cloud
- Ostatní (25 864)
- Fyzikální ústav AV ČR (9 264 CPU jader)
- PBS Pro (3 264 CPU jader): luna, magma
- EGI HTC (6 000 CPU jader)
- Masarykova univerzita ÚVT a C4E (1 208 CPU jader): cloud
- Masarykova univerzita RECETOX (336 CPU jader): cloud
- Karlova univerzita PřF (1 520 CPU jader): cha, fau, mor, pcr, fer
- Západočeská univerzita (1 312 CPU jader): alfrid, konos
- ČVUT FAST (512 CPU jader): farin
- Botanický ústav AV ČR (352 CPU jader): carex, draba, vinca
- Technická univerzita Liberec (480 CPU jader): charon
- Ústav experimentální botaniky (112 CPU jader): samson
- IT4I (2 432 CPU jader): cloud
- Fyzikální ústav AV ČR (9 264 CPU jader)
Statistiky využití zdrojů MetaCentra jednotlivými službami
Dávkový systém PBS - MetaCentrum Grid
ELIXIR (PBS)
Kubernetes, včetně webových služeb JupyterHub, Foldify
MetaCentrum Cloud (OpenStack)
EGI a FedCloud
MetaCentrum Grid (PBS)

Celkový počet uživatelů: 4 621 (z toho 2 357 aktivních v PBS)
Celkem dokončených úloh: 7 610 230
Z toho GPU úloh: 526 149
Propočítaný čas: 25 392 CPU let
Propočítaný čas (GPU): 283 GPU let
Počet CPU jader: 39 988
Počet GPU karet: 332
Celkem výpočetních clusterů: 53 (z toho 23 uživatelských)
Hardware (PBS)
Na konci roku 2025 byl v MetaCentru pro gridové dávkové úlohy dostupný HW v několika kategoriích:
- HD uzly s 20 až 96 CPU jádry a 128 GB a 1,5 TB RAM
- Ideální pro výpočetně náročné úlohy, které nevyžadují GPU, najdou uplatnění např. pro simulace ve výpočetní chemii, fyzice, CFD, pro dávkové zpracování dat, genomiku nebo také úlohy s vyššími nároky na paměť (až 1,5 TB RAM)
- HD uzly s akcelerátory 32-112 CPU jádry, 192 GB až 2 TB RAM a 2 až 8 grafickými akcelerátory s až 96 GB grafické paměti
- Specializované uzly pro úlohy, které lze urychlit pomocí paralelních výpočtů na GPU. To zahrnuje strojové učení a hluboké učení (AI/ML), výpočty molekulární dynamiky, ray tracing, analýzu obrazu a videa nebo vědecké simulace s podporou CUDA.
- SMP uzly s 128 až 504 CPU jádry a 4,6 TB GB - 10 TB RAM ve sdílené paměti; ve větším počtu jsou k dispozici také menší SMP uzly s 56 až 96 CPU jádry a 512 GB až 3 TB RAM
- Jsou určeny pro vysoce paralelní úlohy nebo paměťově extrémně náročné aplikace, které neumějí efektivně komunikovat napříč samostatnými uzly (tj. nejsou dobře paralelizovatelné napříč clusterem). Typické použití je v aplikacích, které vyžadují přímý přístup k jednotnému, velmi rozsáhlému paměťovému prostoru, například některé databázové úlohy, analýza rozsáhlých grafů nebo specifické vědecké simulace.
- Speciální výkonný uzel DGX s 8x NVIDIA H100
- Toto je špičková platforma pro nejnáročnější úlohy umělé inteligence a hlubokého učení. Díky vysoké propustnosti mezi GPU (NVLink) a velké paměti je ideální pro trénování rozsáhlých jazykových modelů (LLM), fundamentální výzkum v AI nebo komplexní vědecké simulace využívající hybridní CPU-GPU architekturu na maximální úrovni. Přístup se zřizuje na požádání.
Uzly jsou typicky propojeny Ethernetem 10 Gbit/s, u vysokovýkonných clusterů pak InfiniBand 100–200 Gbit/s nebo Omni-Path.
Typy grafických karet v MetaCentrum Grid
| Typ GPU karty | Počet |
|---|---|
| NVIDIA H100 96 GB | 20 bee |
| NVIDIA H100 80 GB DGX on Demand | 8 capy |
| NVIDIA A100 40 GB | 20 zia, 2 elbi |
| NVIDIA A40 48 GB | 6 luna, 80 galdor |
| NVIDIA L40S 48 GB | 16 alfrid, 80 fobos |
| NVIDIA L40 48 GB | 8 alfrid |
| NVIDIA RTX A4000 16 GB | 24 fer |
| NVIDIA Quadro RTX 5000 16 GB | 24 fau |
| NVIDIA GeForce RTX 2080 Ti 11 GB | 8 cha, 3 glados |
| NVIDIA Tesla P100 12 GB | 2 grimbold |
| NVIDIA GeForce GTX 1080 Ti | 32 konos |
Využití výpočetních zdrojů zapojených v meta-pbs
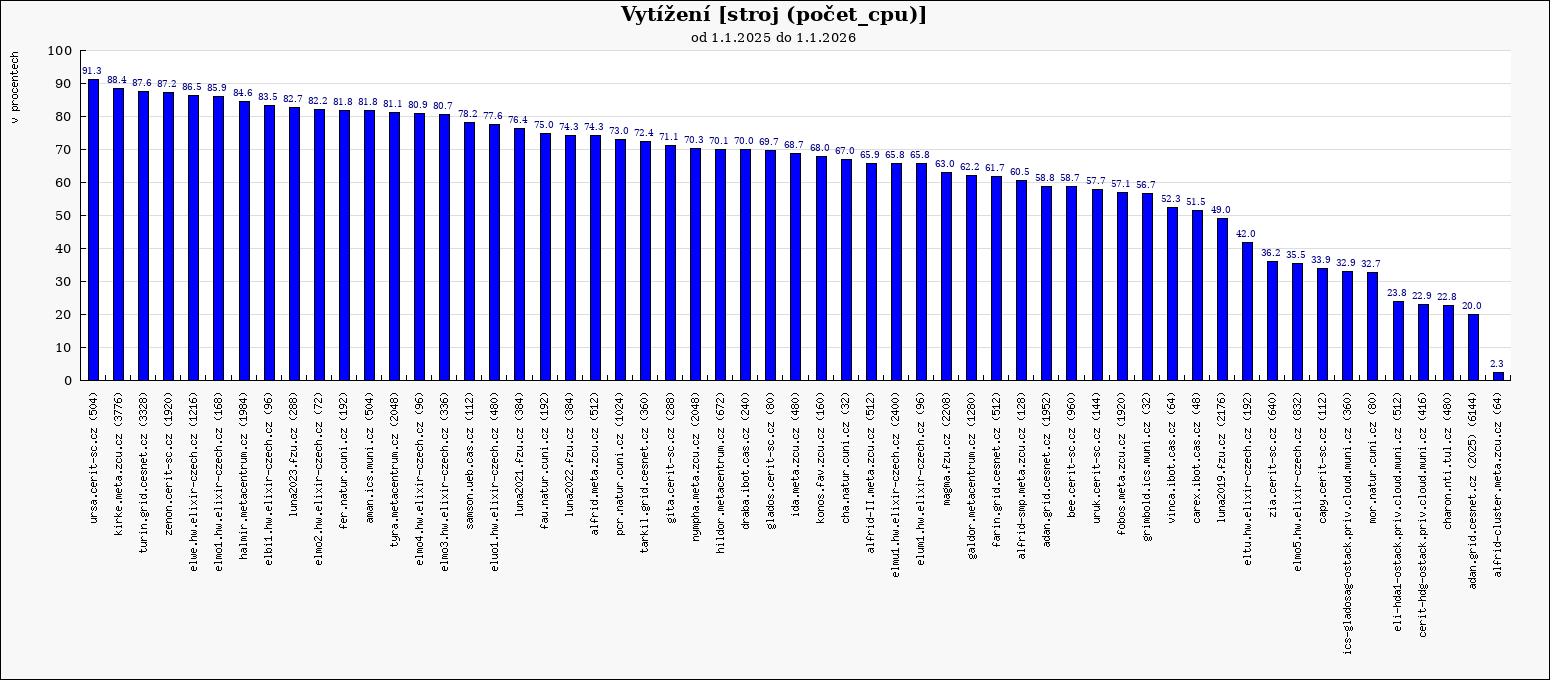
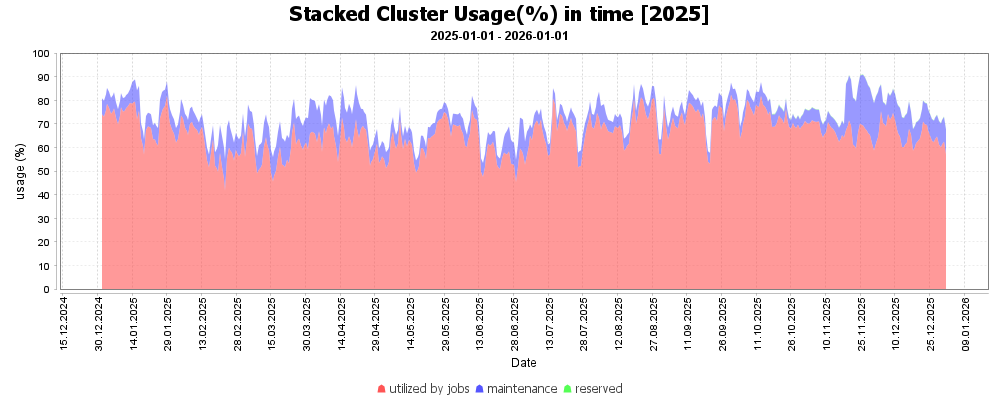
Následující graf ukazuje průměrné vytížení výpočetních clusterů a strojů v MetaVO v roce 2025. Základem pro výpočet průměrného vytížení (100%) je celkový počet dostupných CPU-core-seconds mínus počet CPU-core-seconds strojů, které nebyly v provozu. Rezervované stroje jsou započítané tak, jako by byly plně využity, bez ohledu na jejich skutečné využití. Údaj v závorce udává počet CPU v clusteru na konci roku. Nula značí, že cluster byl v průběhu roku vyřazen.
Průměrné vytížení volně dostupných strojů v MetaVO se v roce 2025 pohybovalo kolem 65–70 %, což je optimální úroveň. Vyšší vytížení by vedlo k delším čekacím dobám ve frontách, nižší vytížení mají typicky nové nebo specializované clustery (například GPU clustery nebo stroje rezervované pro konkrétní výzkumné projekty).
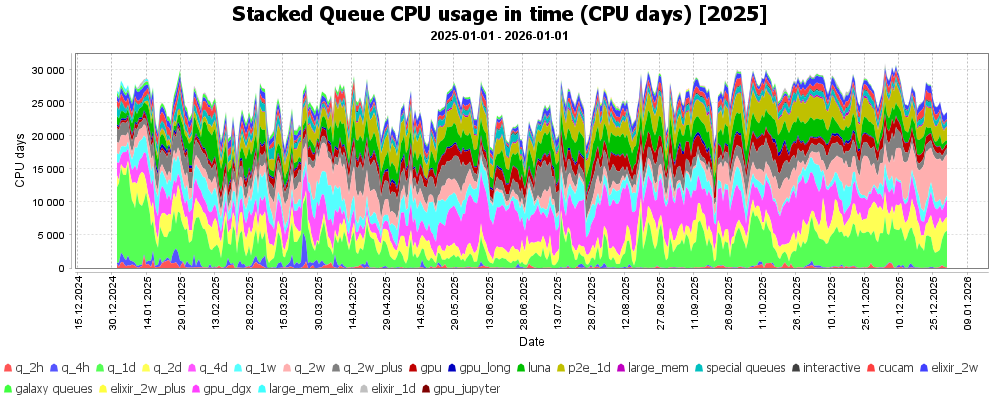
Následující graf ukazuje využití výpočetních uzlů (propočítaný CPU čas). Modrá čára označuje hranici, kolik CPU času mohlo být teoreticky v daný den propočítáno, kdyby byla využita všechna dostupná CPU jádra.

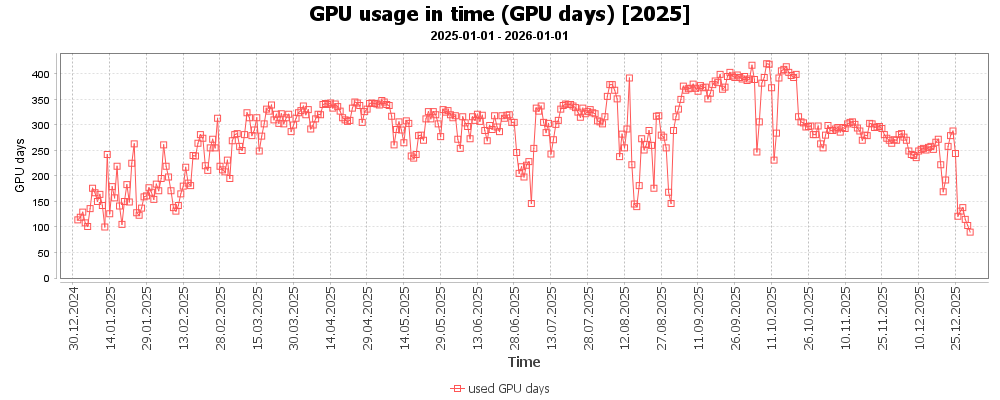
Podobně lze ukázat využití GPU karet (propočítané GPU dny).
Počet úloh příchozích do plánovače osciloval většinu roku okolo 35 tis. úloh denně. V březnu, dubnu, červnu bylo spuštěno mnoho malých obvykle zřetězených úloh několika málo uživatelů, které výrazně navýšily standardní denní počet úloh. V polovině roku jsme nastavili strop na max. počet úloh v systému na jednoho uživatele.
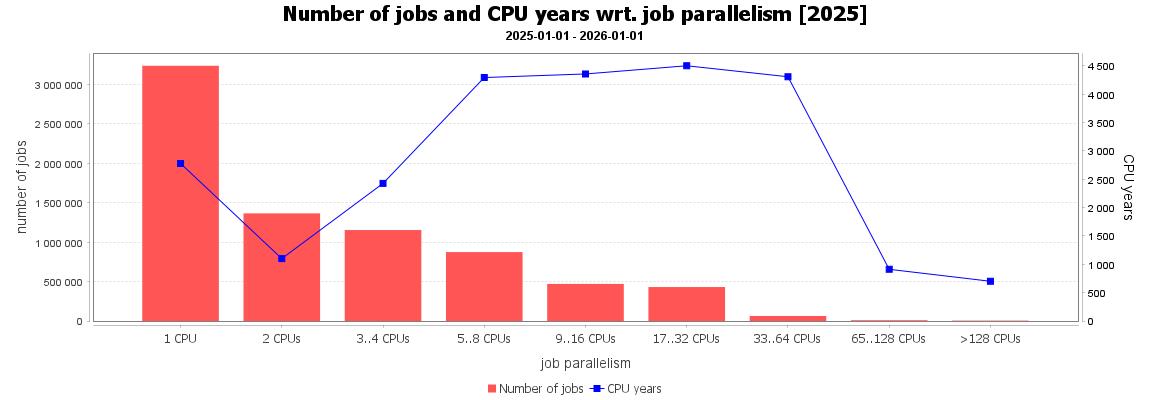
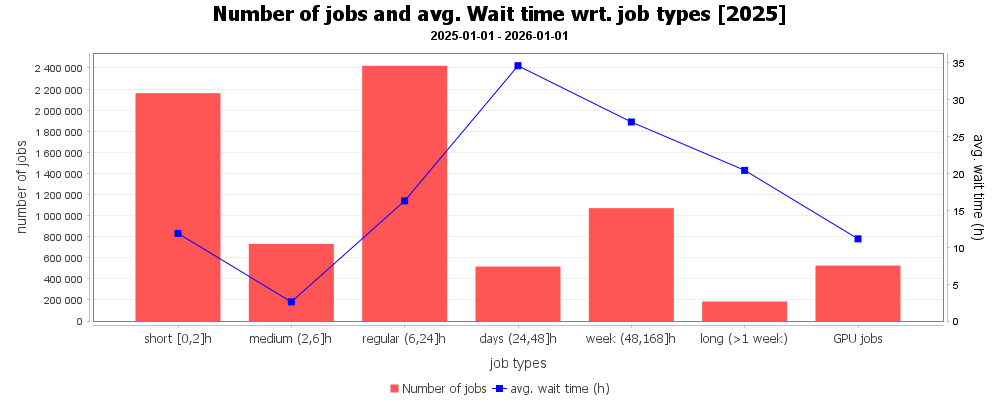
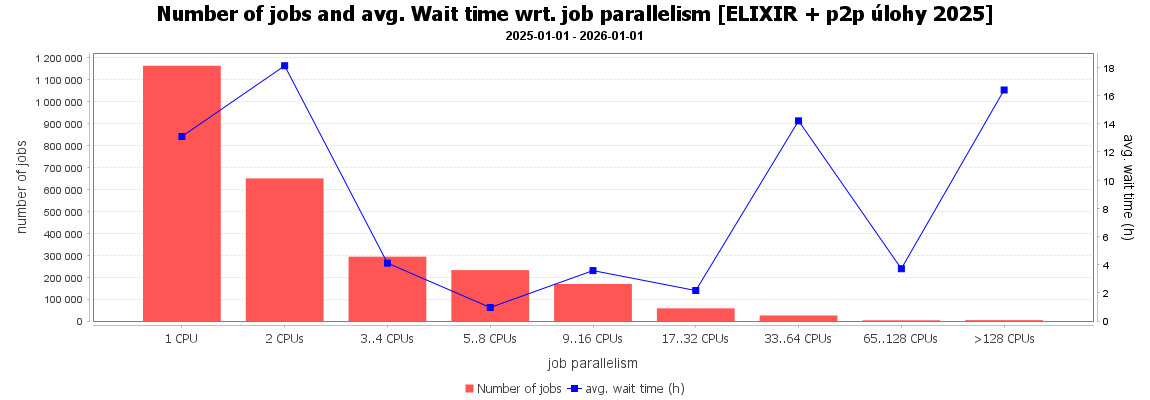
Vztah mezi šířkou úlohy (paralelizace) a propočítaným časem. Z grafu je patrné, že nejvíce úloh požadovalo jen 1 CPU, zatímco nejvíce CPU času zkonzumovaly paralelní úlohy využívající více než 4 a méně než 64 CPU jader v úloze.
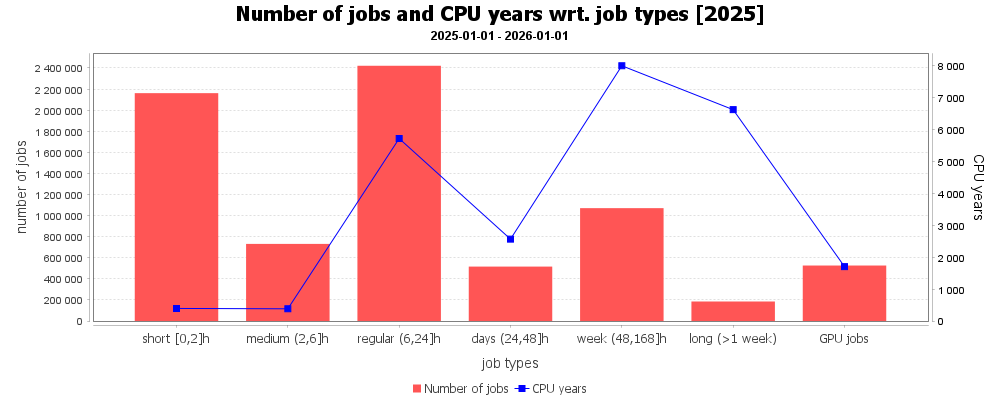
Podobně vztah mezi délkou úlohy a propočítaným časem. Z grafu je patrné, že nejvíce úloh bylo do 2 hodin a v rozmezí 6-24 hodin. Nejvíce CPU času zkonzumovaly úlohy s délkou 6-24 hodin, 48-168 hodin a úlohy delší než 1 týden.
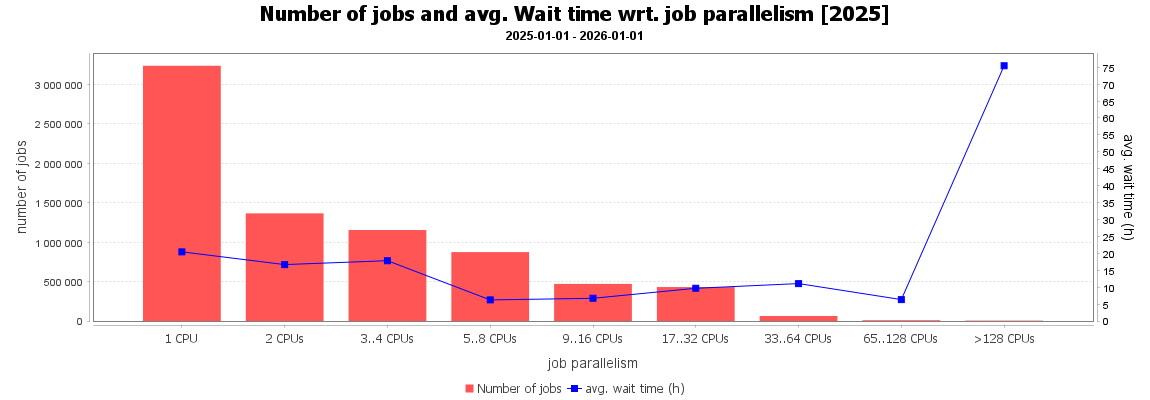
Doba čekání úloh na spuštění v závislosti na počtu požadovaných CPU jader. Nejdéle čekaly na spuštění úlohy požadující více než 128 CPU a to většinou kvůli špatnému zadání.
Doba čekání úloh na spuštění podle délky běhu úlohy.
Průměrné využití clusterů v průběhu roku. Červená značí využití, modrá uzly v údržbě (maintenance). Žádne rezervace v roce 2025 nebyly.
Využití front podle CPU času.
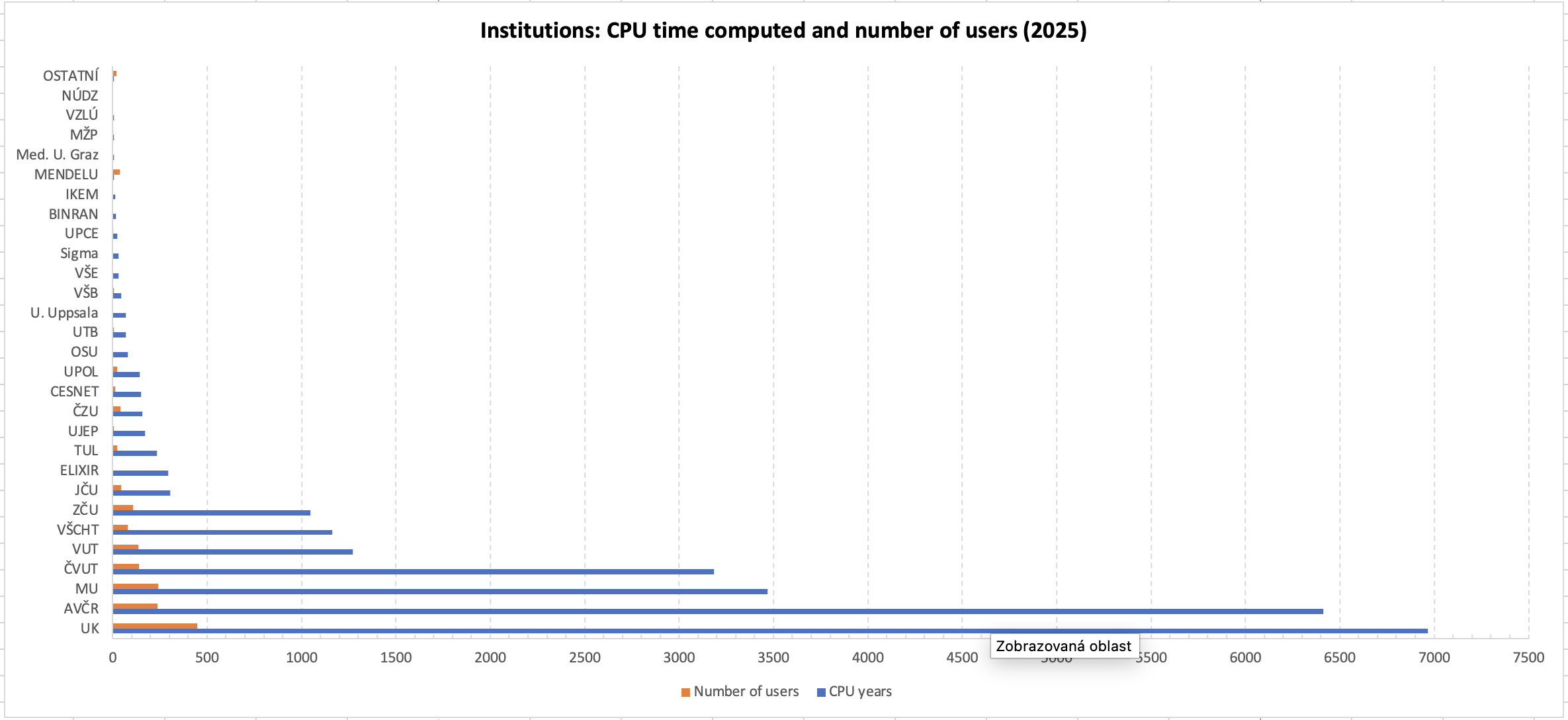
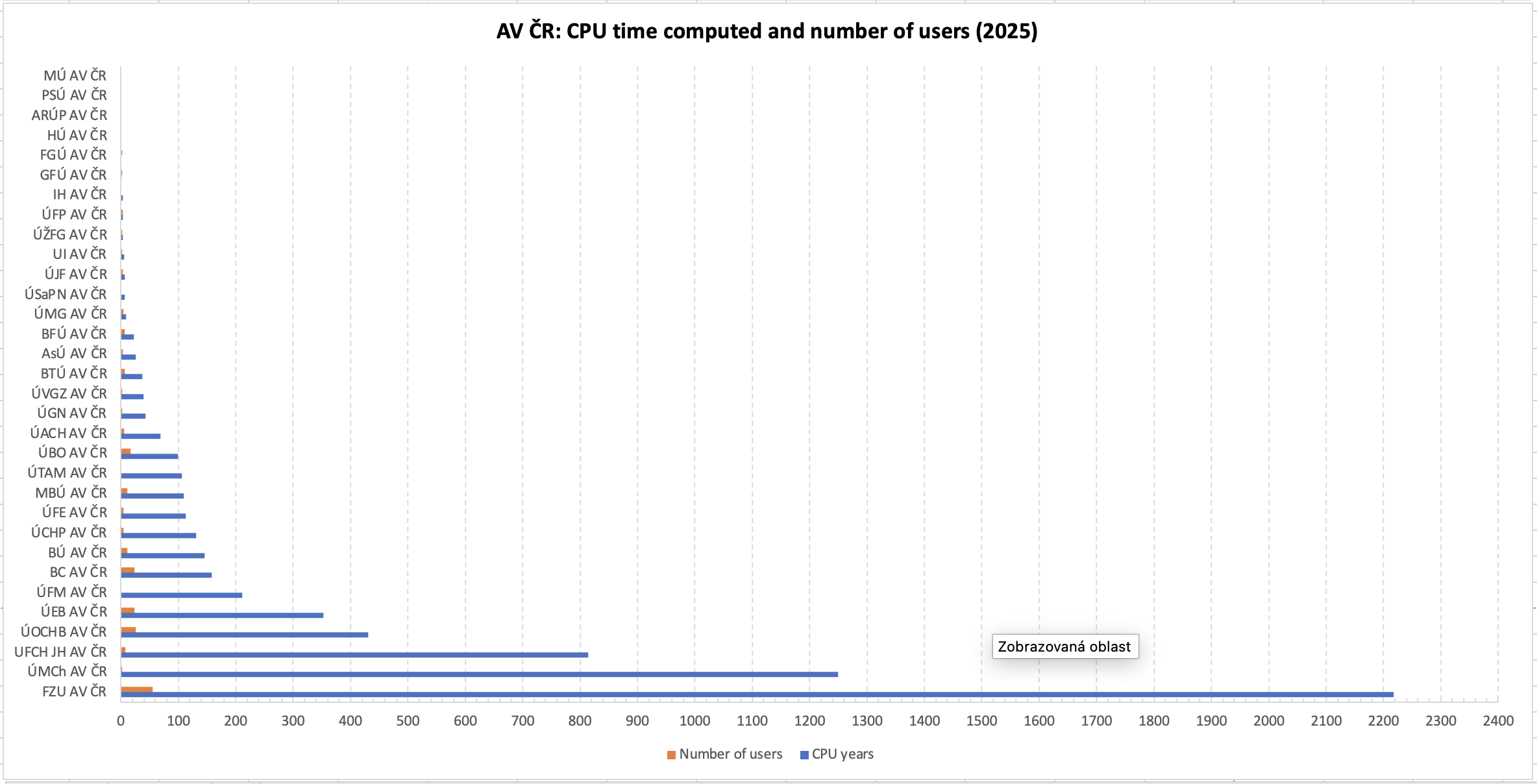
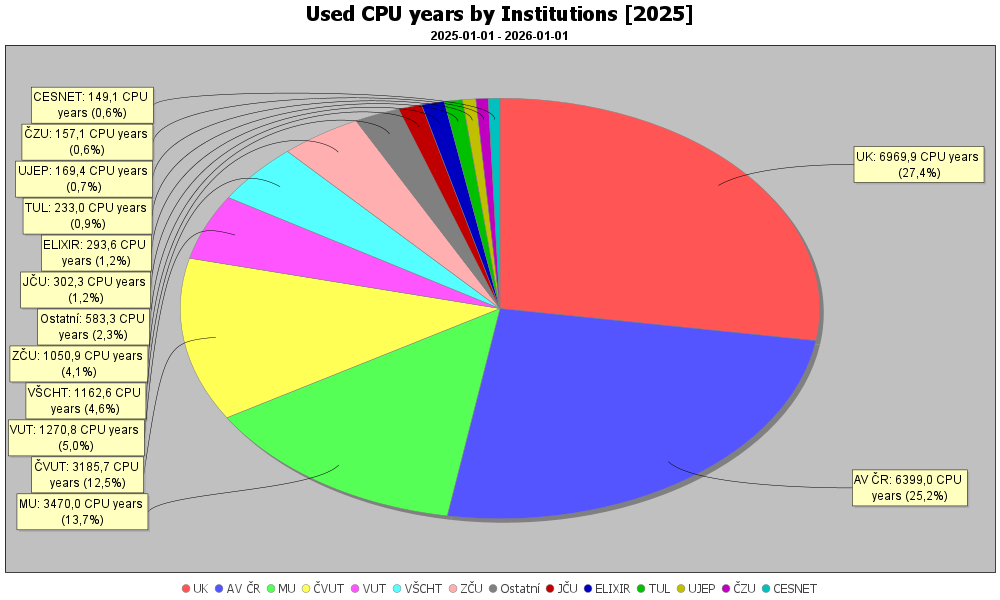
Využití MetaCentra institucemi (PBS)
Využití MetaCentra organizacemi (PBS) dle propočítaného času. Na prvním grafu je Akademie věd započítána jako jedna organizace, na druhém pak jak počítaly jednotlivé ústavy v rámci Akademie věd. Do počtu uživatelů jsou započítáni pouze ti, kteří v roce 2025 spustili alespoň jednu úlohu.
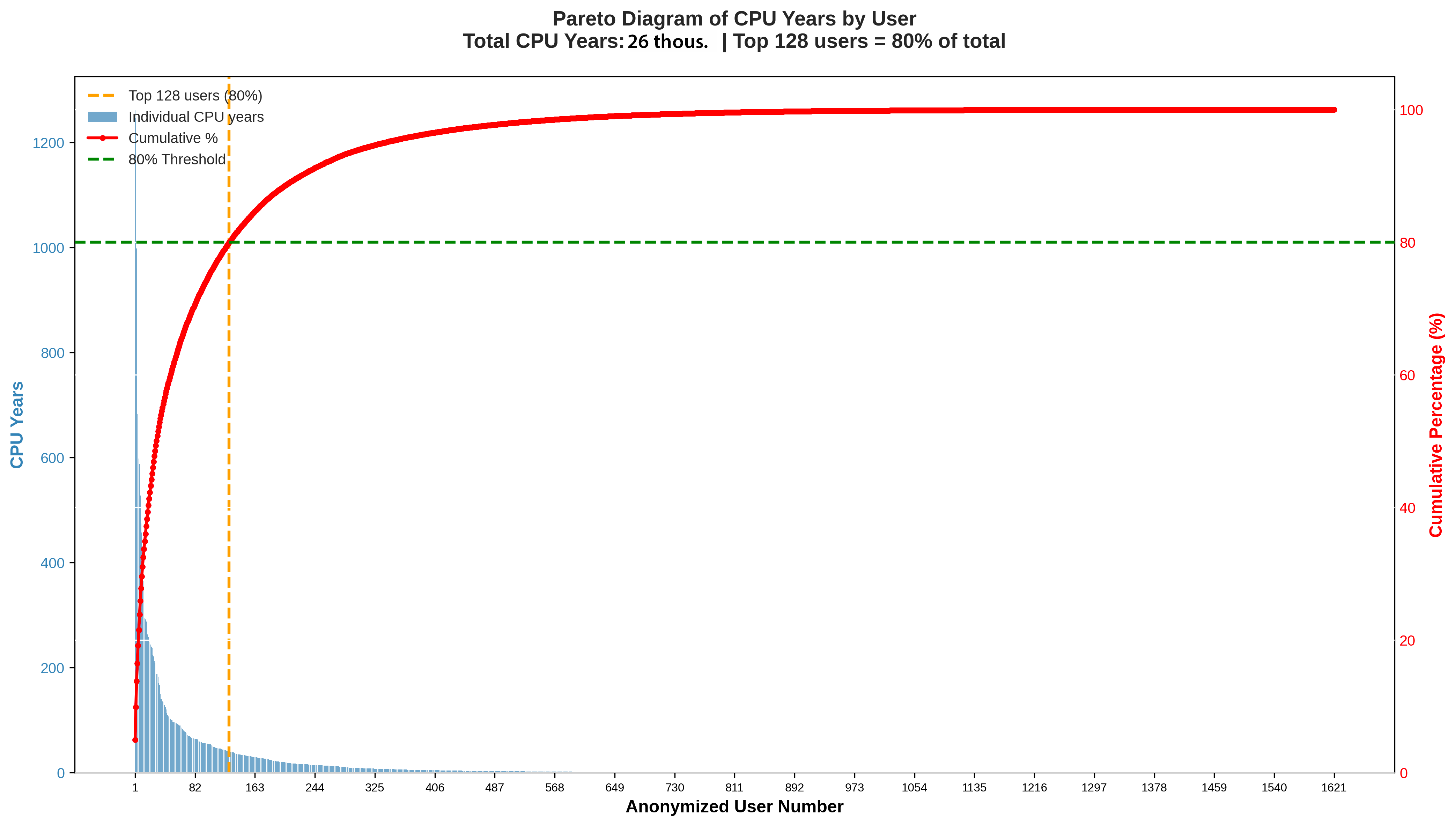
Využití MetaCentra jednotlivými uživateli
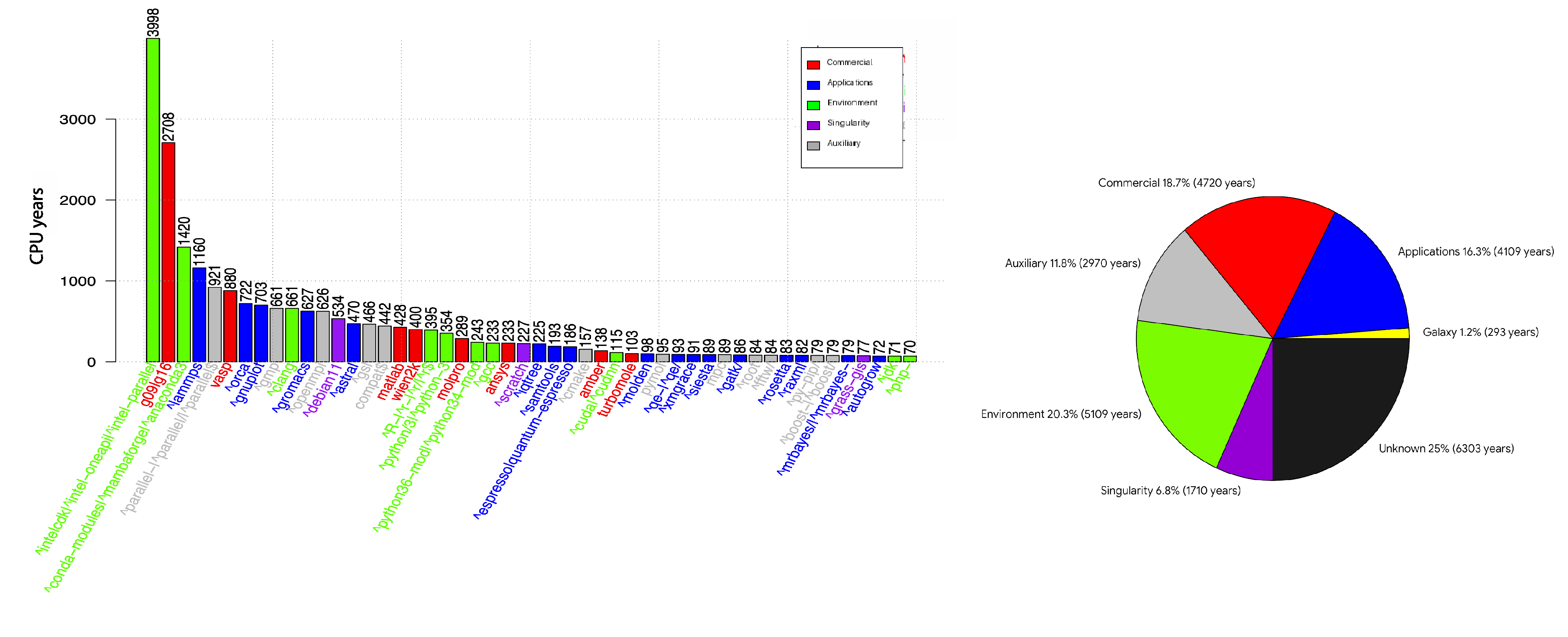
Paretův diagram ověřuje hypotézu 80/20. V grafu je kumulativní součet CPU časů propočítaných jednotlivými uživateli. Tito jsou seřazeni od největšího počtáře k nejmenšímu. Z analýzy vyplývá, že pouhých 128 uživatelů (7,9 % z 1 621) je zodpovědných za 80 % celkového výpočetního času. Zbytek (více než 92 % uživatelů) si dělí zbývajících 20 % kapacity. Průměr na jednoho uživatele činí 15,66 CPU let.
TOP5 uživatelů podle propočítaného času
- Uživatel 1: 1 261,98 CPU let (5 % z celku)
- Uživatel 2: 1 246,52 CPU let (9,9 % kumulativní součet)
- Uživatel 3: 997,99 CPU let (13,8 % kumulativní součet)
- Uživatel 4: 682,22 CPU let (16,5 % kumulativní součet)
- Uživatel 5: 677,85 CPU let (19,2 % kumulativní součet)
Statistiky využití SW v PBS
Data o využití softwaru byla získána ze syslogu – konkrétně informace o propočítaném CPU čase (celkovém výpočetním času) pro jednotlivé moduly, které byly spouštěny prostřednictvím systému PBS.
V roce 2025 uživatelé na výpočetním clusteru využili přibližně 4 000 různých softwarových modulů ve více než 4 milionech úloh. Analýza ukázala, že 50 nejčastěji používaných modulů spotřebovalo 91 % celkového CPU času všech úloh. Celkový CPU čas komerčních softwarů tvořil 22 % z celkového propočítaného výpočetního času.
Grafy:
- Propočítaný čas komerčními SW (vpravo).
- TOP 50 modulů podle největšího podílu na propočítaném CPU čase.
- TOP 50 nejpoužívanějších modulů podle počtu uživatelů, kteří je využili.
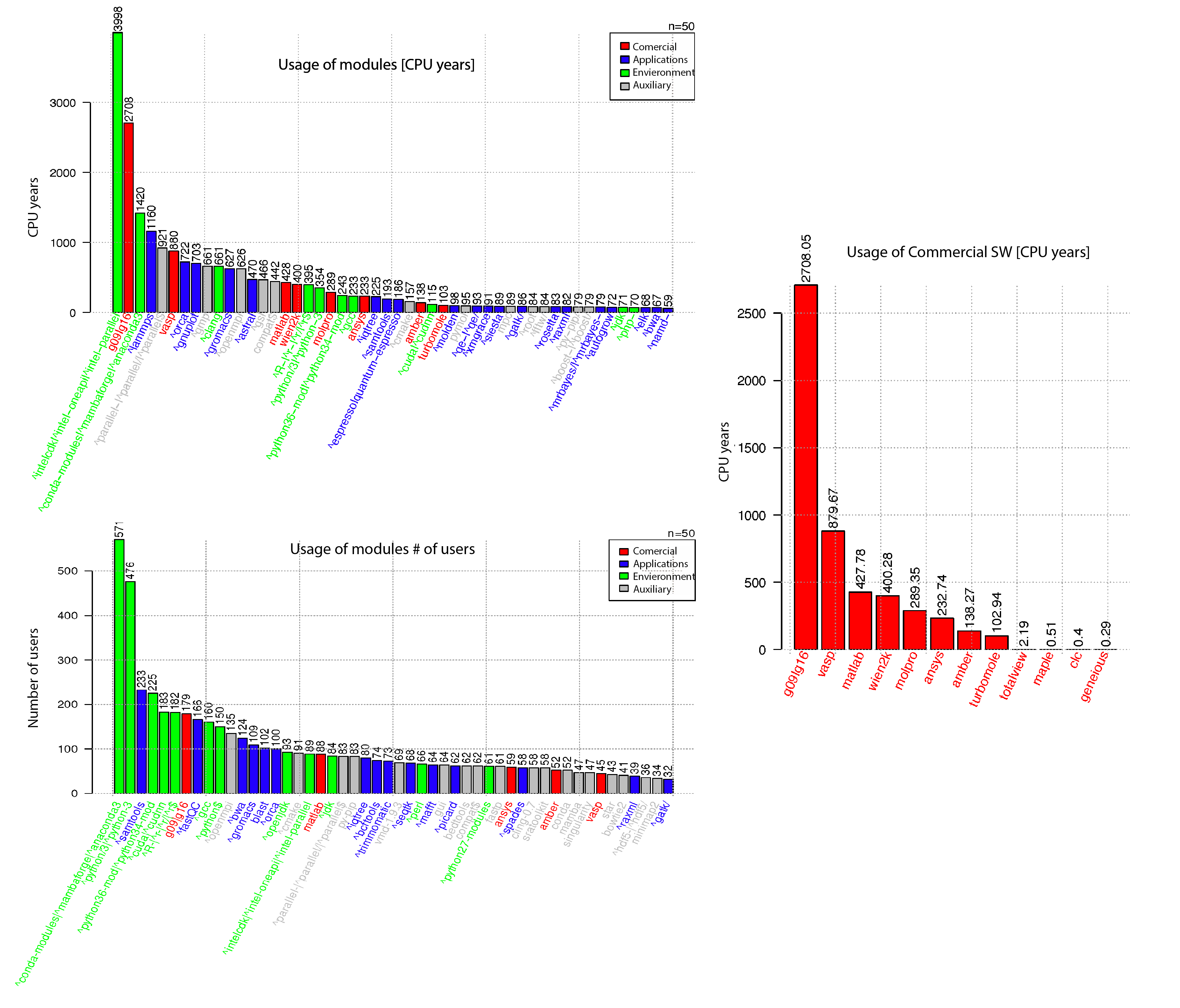
Propočítaný čas moduly a Singularity. Oproti předchozímu grafu jsme připočetli Singularity image.
Grafické prostředí Open OnDemand (PBS)
OpenOnDemand je grafické webové rozhraní pro spouštění interaktivních úloh, umožňující grafický náhled a manipulaci (Matlab, Ansys, Jupyter, apod.) a zároveň je zde možné jednoduše spouštět i dávkové úlohy. V obou případech úlohy běžely v PBS a jsou započítané v souhrnné statistice dávkového prostředí.

Nejpoužívanější aplikací v OnDemandu podle CPU času je RStudio, dále následuje RemoteDesktop, Matlab a JupyterNotebooky. Podle počtu úloh patří mezi nejoblíbenejší JupyterNotebook a RStudio.
| Aplikace | Počet úloh | Počet uživatelů | CPU let |
|---|---|---|---|
| RStudio | 2 696 | 184 | 26,87 |
| Jupyter | 3 356 | 282 | 9,13 |
| Desktop | 894 | 163 | 11,13 |
| Matlab | 503 | 51 | 9,19 |
| Ansys | 528 | 68 | 4,37 |
| biop-desktop | 97 | 27 | 0,02 |
| VMD | 233 | 56 | 0,08 |
| CLC genomics | 12 | 9 | 0,02 |
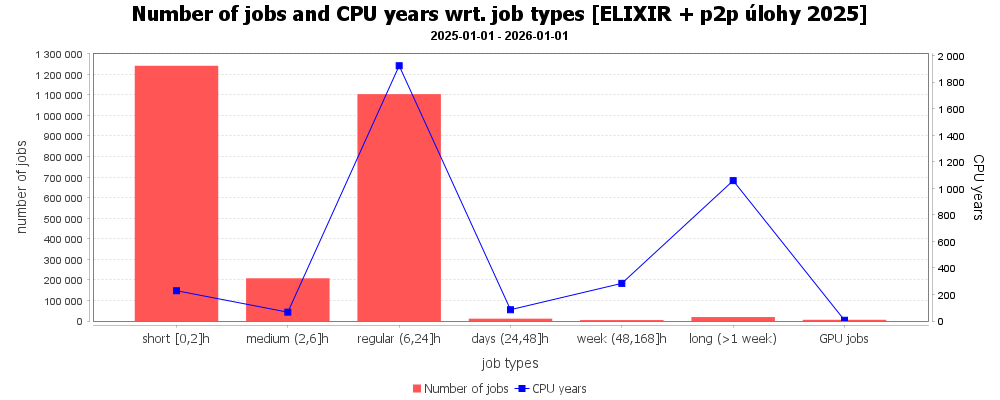
Projekt ELIXIR (PBS)
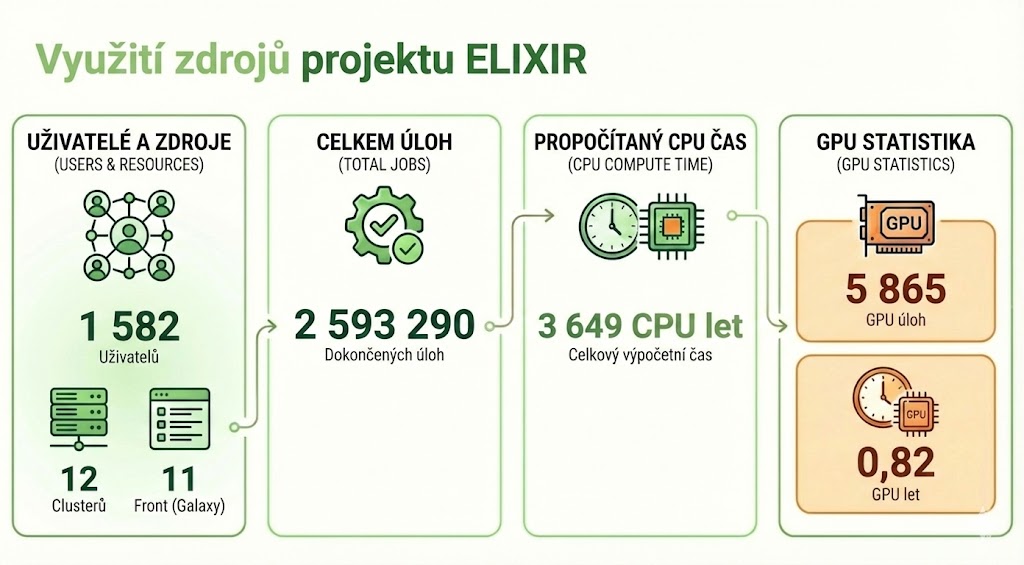
V projektu ELIXIR bylo k dispozici na konci roku 8 336 CPU jader, z toho část v PBS (5 984 CPU jader) a část v OpenStack Cloudu (2 352 CPU jader). Zde uvádíme statistiky za PBS. Na strojích ELIXIRu běžely jednak úlohy vlastníků a jednak výplňové krátké úlohy ostatních uživatelů. Uživatelé ELIXIRu mohli zároveň využívat ostatní clustery v MetaCentru, včetně těch s GPU akcelerátory. Stroje projektu ELIXIR GPU akcelerátory nemají.
Na strojích ELIXIRu bylo spočítáno:
- Celkem úloh: 2 593 290
- Celkem GPU úloh: 5 865
- Celkem uživatelů: 1 582
- Celkem clusterů: 12
- Celkem CPU roků: 3 649
- Celkem GPU roků: 0,82
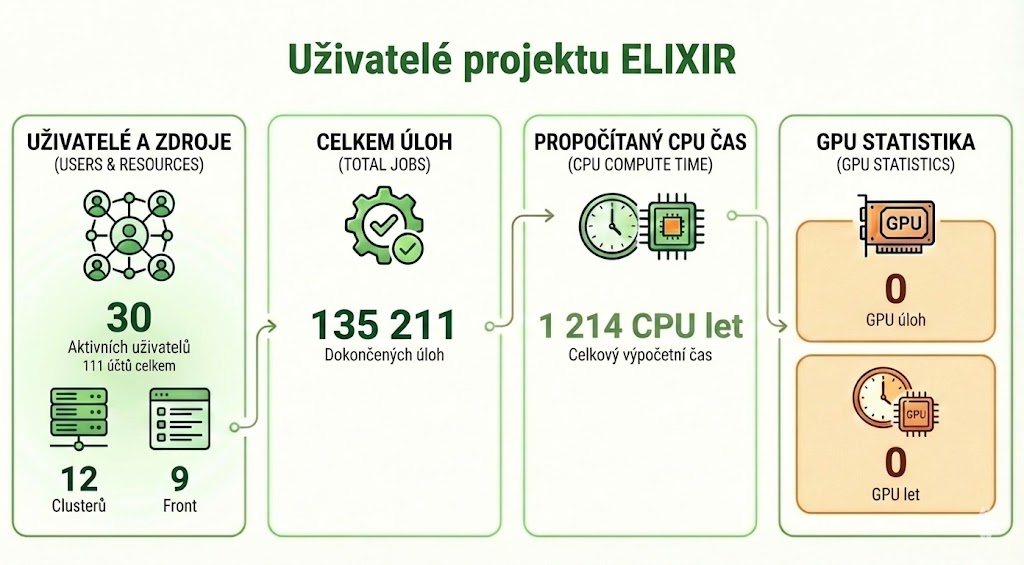
V dedikovaném režimu uživatelé patřící k projektu ELIXIR na svých clusterech propočítali:
- Celkem úloh: 135 211
- Celkem GPU úloh: 0
- Dopočítáno úloh: 135 211
- Registrováno uživatelů: 1 111
- Celkem uživatelů s alespoň 1 úlohou: 30
- Celkem CPU roků: 1 213,7
- Celkem GPU roků: 0
Následují grafy ilustrující využití strojů uživateli z projektu ELIXIR. Kromě jejich úloh na strojích patřících ELIXIRu běžely výplňové úlohy jiných uživatelů, ty zde nejsou započítány.
Uživatelé projektu ELIXIR měli po celý rok k dispozici ze začátku cca 3,5 tisíce CPU jader, od února přes 6 tisíc CPU jader a využili je průměrně přibližně z poloviny. Jelikož ELIXIR nedisponuje GPU kartami, mnoho výpočtů uživatelé pouštěli v MetaCentru na ostatních strojích v běžných frontách (tyto úlohy zde nejsou zahrnuté).
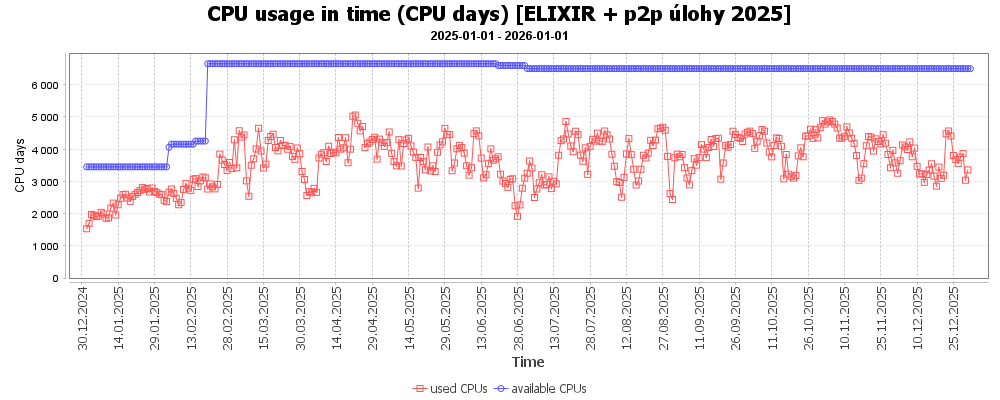
Následující graf ilustruje počet úloh, které přicházely do systému.
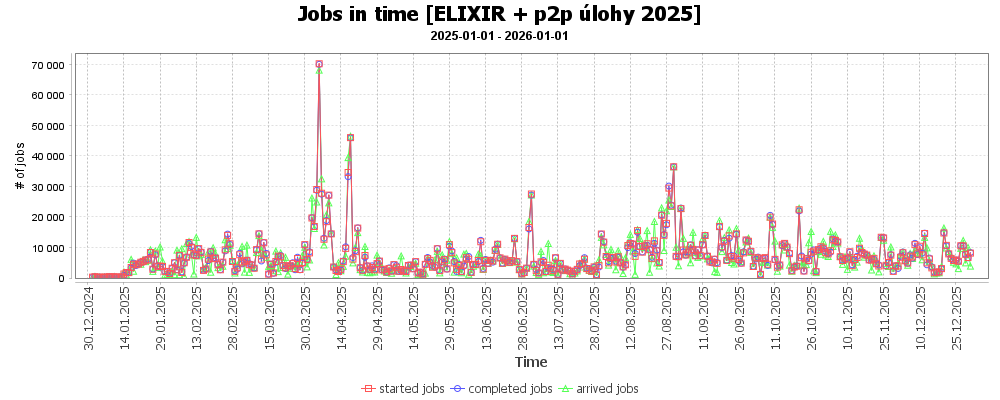
Počet úloh v systému podle požadované délky běhu, a celkový propočítaný čas úlohami dané kategorie, demonstruje následující graf. Je z něj patrné, že většina úloh běžela do 6 hodin, ale nejvíce CPU času propočítaly dlouhé úlohy s požadovanou délkou běhu alespoň týden.
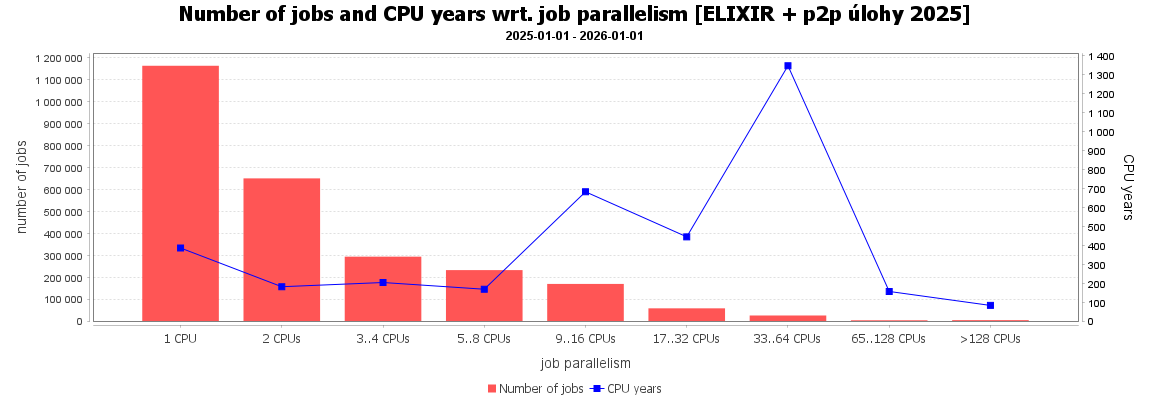
Podobně v systému bylo nejvíce 1 CPU úloh a také 5 až 8 CPU úloh, ale nejvíce CPU času propočítaly úlohy požadující 32 a více CPU jader.
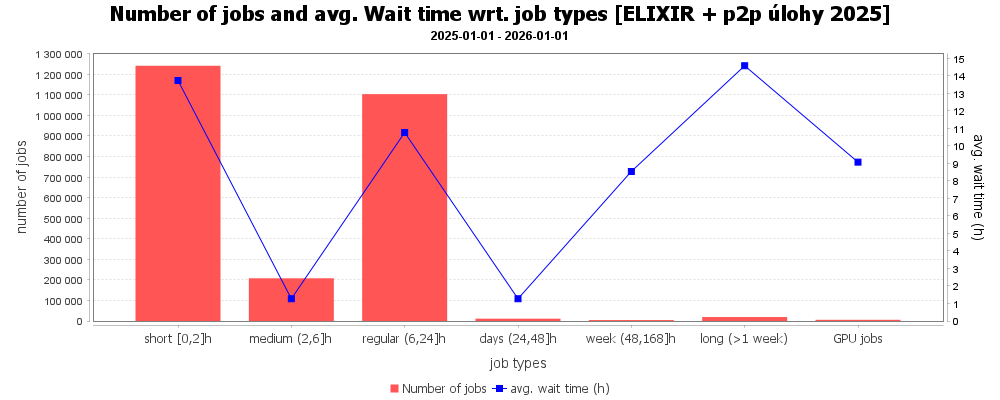
Graf doby čekání v závislosti na délce úlohy ukazuje, že nejdéle čekaly úlohy s dobou běhu alespoň týden. Průměrná doba čekání u krátkých úloh byla do 2 hodin, u těch delších byla průměrně do 30 hodin. GPU úlohy byly odbavovány okamžitě a směřovaly na jiné stroje v MetaCentru obsahující grafické karty.
Obdobně graf doby čekání v závislosti na počtu požadovaných CPU jader ukazuje, že nejdéle čekaly úlohy požadující více než 64 CPU jader, kterých však bylo ojediněle. Průměrná doba čekání u krátkých úloh byla do 2 hodin.
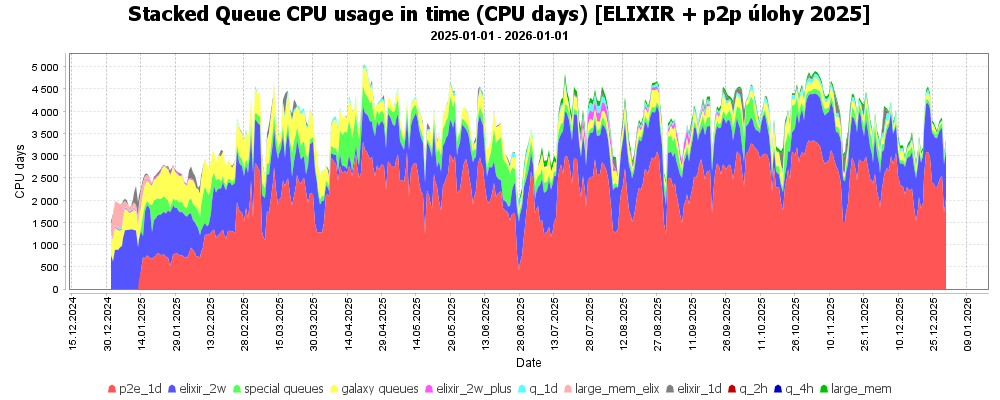
Vytížení clusterů projektu ELIXIR podle prioritních front jednotlivých služeb ilustruje následující graf. Nejvíce CPU času bylo propočítáno běžnými uživateli ve 2+ týdenní frontě elixir_2w. Dále sem směřovaly úlohy z Galaxy serverů (usegalaxy.cz, umsa a RE galaxy).
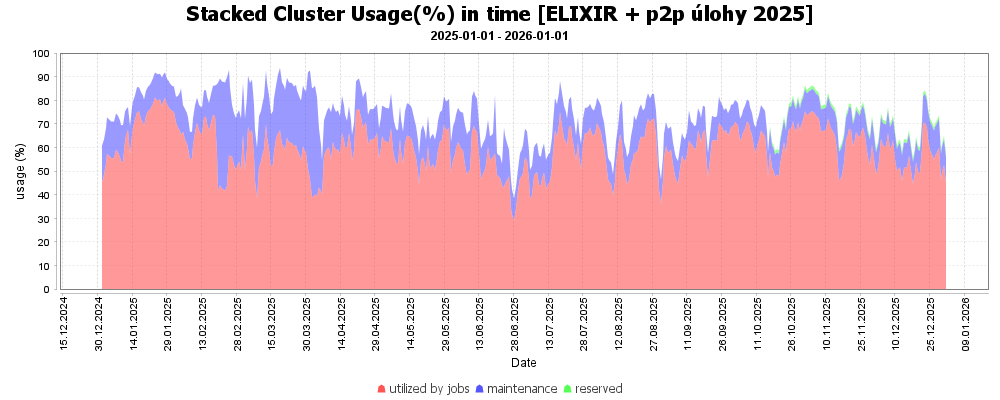
Průměrné využití clusterů ELIXIR v čase. Červeně jsou znázorněné uzly v provozu, modře v údržbě. V únoru byl zprovozněn nový výpočetní cluster, proto je v února v v březnu více uzlů v maintenance. Odpovídá to testovacímu provozu, kdy bylo potřeba uzly odstavovat a ladit jejich nastavení.
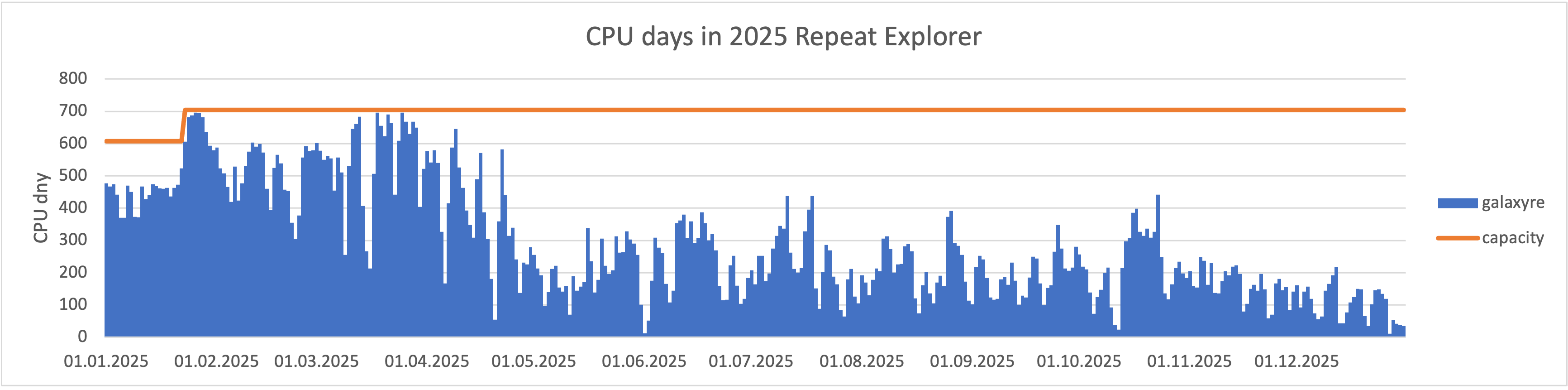
Služba ELIXIR RepeatExplorer Galaxy podrobněji
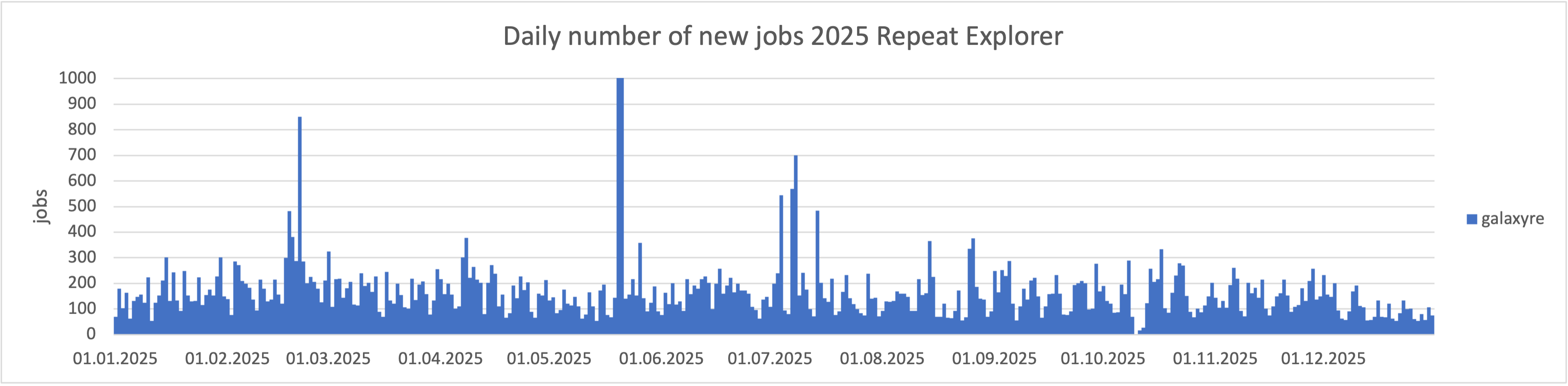
Službě RE Galaxy bylo vyhrazeno po většinu roku 700 CPU jader. V únoru jsme zaznamenali výrazné navýšení počtu příchozích úloh, a proto došlo k navýšení výpočetní kapacity ze 600 na 700 CPU jader.
Na následujících grafech je znázorněné vytížení těchto dedikovaných výpočetních prostředků. Červená čára ukazuje kolik zdrojů bylo k dispozici v čase, modrá část grafu jsou pak úlohy běžící ve frontě "galaxyre". Od května došlo ke snížení počtu přicházejících požadavků.
Následující graf demonstruje počet úloh přicházejících do systému.
Graf průměrné doby čekání dokládá jak se snížení počtu úloh v systému pozitivně promítlo do rychlosti plánování a čekání úloh se v polovině roku velmi snížilo. Delší doba čekání se vyskytla v prosinci, kdy do systému přicházelo více požadavků na dlouhé úlohy nebo na úlohy vyžadující mnoho CPU jader.
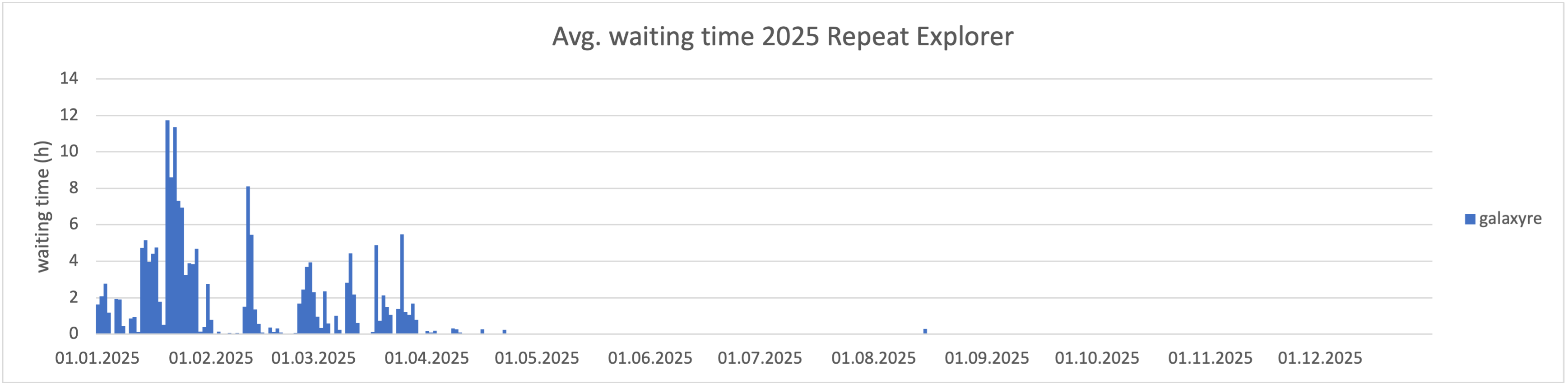
Kubernetes CERIT-SC
Centrum CERIT-SC v roce 2025 spravovalo čtyři typy výpočetních zdrojů. Část zdrojů byla k dispozici v Kubernetes (3 008 CPU jader a 47 GPU karet), část zdrojů byla přístupná v zabezpečeném prostředí SensitiveCloud (1 112 CPU jader a 40 GPU karet) a část starších zdrojů byla k dispozici v OpenStacku (1 112 CPU jader a 40 GPU karet). Další zdroje byly dostupné v gridu přes PBS. Zde uvádíme statistiky z Kubernetes a ze SensitiveCloudu.

Technické parametry a infrastruktura (CERIT-SC)
Infrastruktura je navržena pro náročné výpočetní i datové operace. Obsluhuje jednak běžné prostředí Kubernetes a jednak prostředí pro citlivá data SensitiveCloud, běžící na podobné platformě Kubernetes, ale v zabezpečeném režimu.
- Typický uzel disponuje 64–96 jádry a nadstandardní operační pamětí (512 GB – 1,5 TB RAM) a s lokálními disky o kapacitě 3,6 TB až 60 TB SSD NVME.
- K dispozici je rovněž úložiště typu all-flash o kapacitě 500 TB (plus 192 TB pro SensitiveCloud). Obě úložiště využívají špičkový souborový systém IBM Spectrum Scale, zajišťující vysokou propustnost dat.
- Všechny uzly jsou propojeny vysokorychlostní sítí o kapacitě 100–200 Gbps, což minimalizuje latenci při distribuovaných výpočtech.
CERIT-SC v roce 2025 modernizoval GPU nabídku o nejvýkonnější dostupné technologie. Pro úlohy AI inference jsou nově k dispozici specializované DGX uzly osazené kartami NVIDIA B200 a B300 s extrémní kapacitou paměti až 270 GB na kartu, což umožňuje provozování největších jazykových modelů (LLM) a jsou vyhrazené pro AI inferenci.
Infrastruktura nabízí širokou škálu akcelerátorů NVIDIA optimalizovaných pro různé typy zátěže:
Typy grafických karet v Kubernetes (2025)
| Typ GPU karty | Počet |
|---|---|
| NVIDIA B300 270 GB NVL Inference | 8 |
| NVIDIA B200 180 GB NVL Inference | 8 |
| NVIDIA H100 96 GB NVL | 8 |
| NVIDIA P100 16 GB PCIe | 2 |
| NVIDIA A40 48 GB | 21 |
| NVIDIA L4 | 1 |
| NVIDIA A10 | 5 |
| NVIDIA A100 80GB | 10 |
| NVIDIA RTX Pro 6000 96 GB | 10 |
Využití Kubernetes
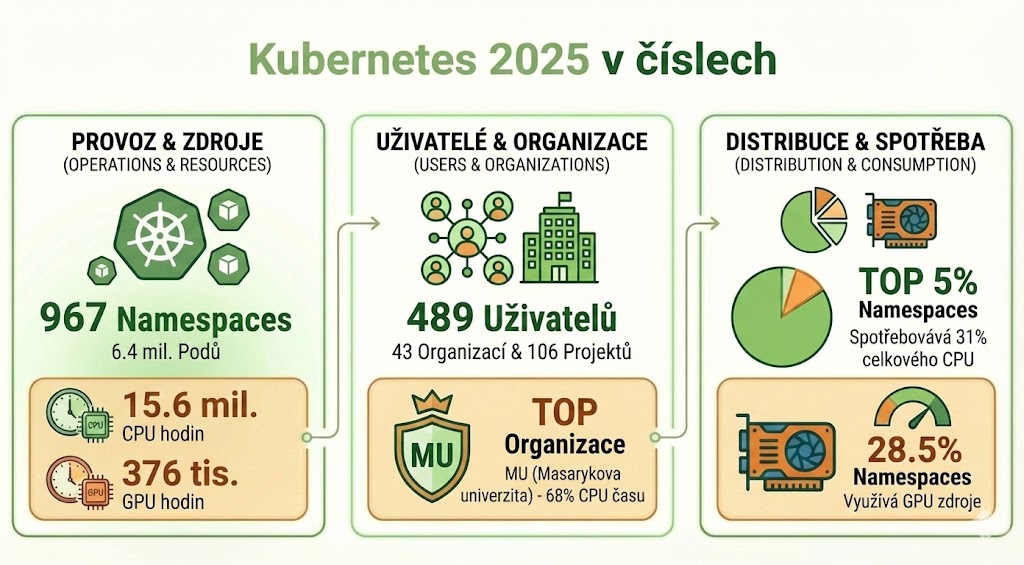
Rok 2025 byl ve znamení výrazného nárůstu poptávky po výpočetních zdrojích. Celkový objem spotřebovaného CPU času v prostředí Kubernetes dosáhl 1 760 CPU let, což představuje meziroční nárůst o 56,7 % oproti roku 2024 (1 123 CPU let).
- Bylo propočítáno 1 760 CPU let a 43 GPU let.
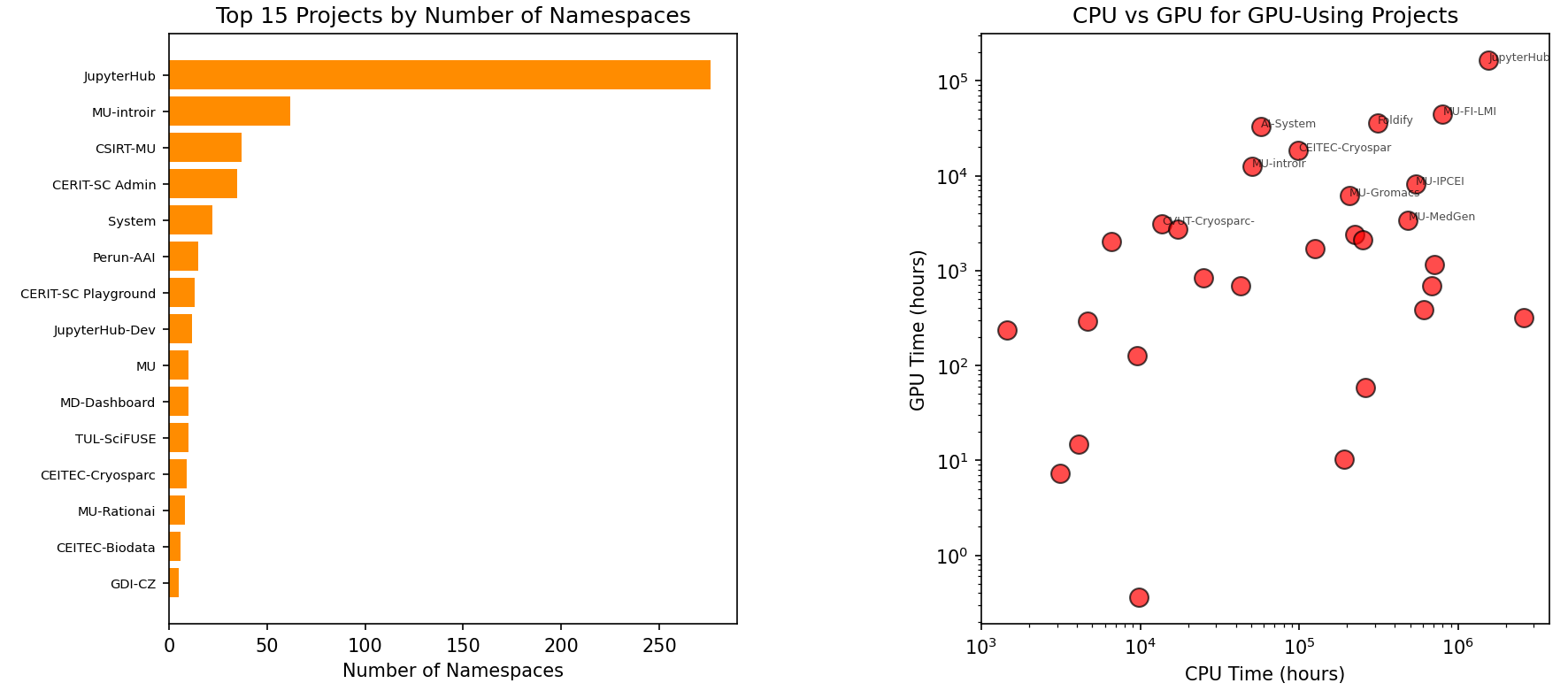
- Infrastruktura obsloužila 6,42 milionu podů (kontejnerových jednotek) v rámci 967 namespaců, což svědčí o vysoké dynamice a efektivním odbavování různorodých úloh.
- Data ukazují na existenci několika klíčových vědeckých projektů – pouhých 5 % uživatelských a projektových "namespaců" spotřebovává 31 % celkového CPU výkonu.
- Služeb využilo 489 individuálních uživatelů a 106 projektů, pocházejících ze 43 různých organizací a významných velkých projektů. Celkem se do Kubernetes přihlásilo skoro 800 uživatelů.
- Téměř třetina všech výpočtů (28,5 %) aktivně využívá GPU akceleraci.
- CPU/GPU ratio: 41:1
- Průměrné časy (namespace):
- CPU čas: 1,84 let
- GPU čas: 0,04 let (~15 dní)
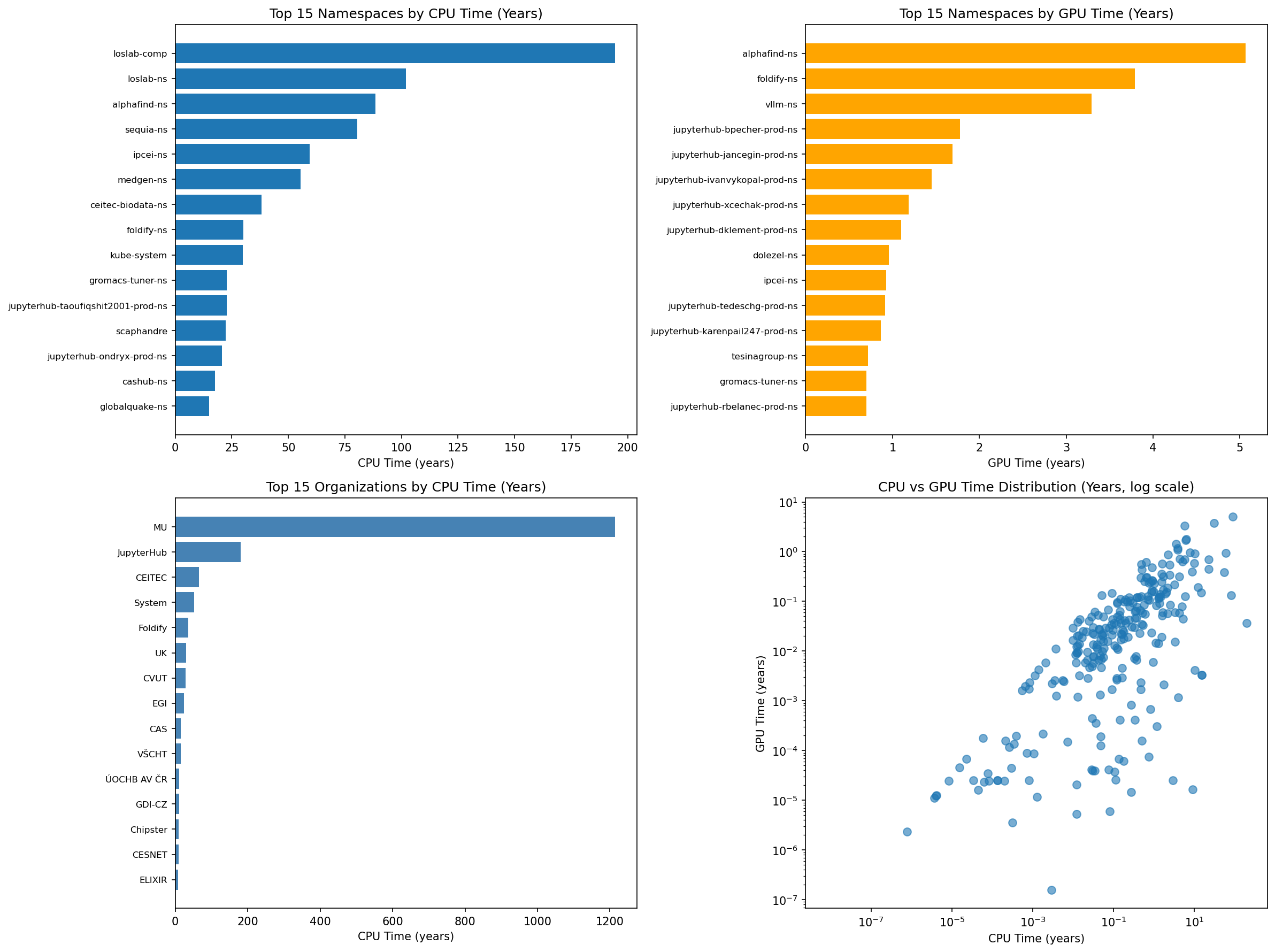
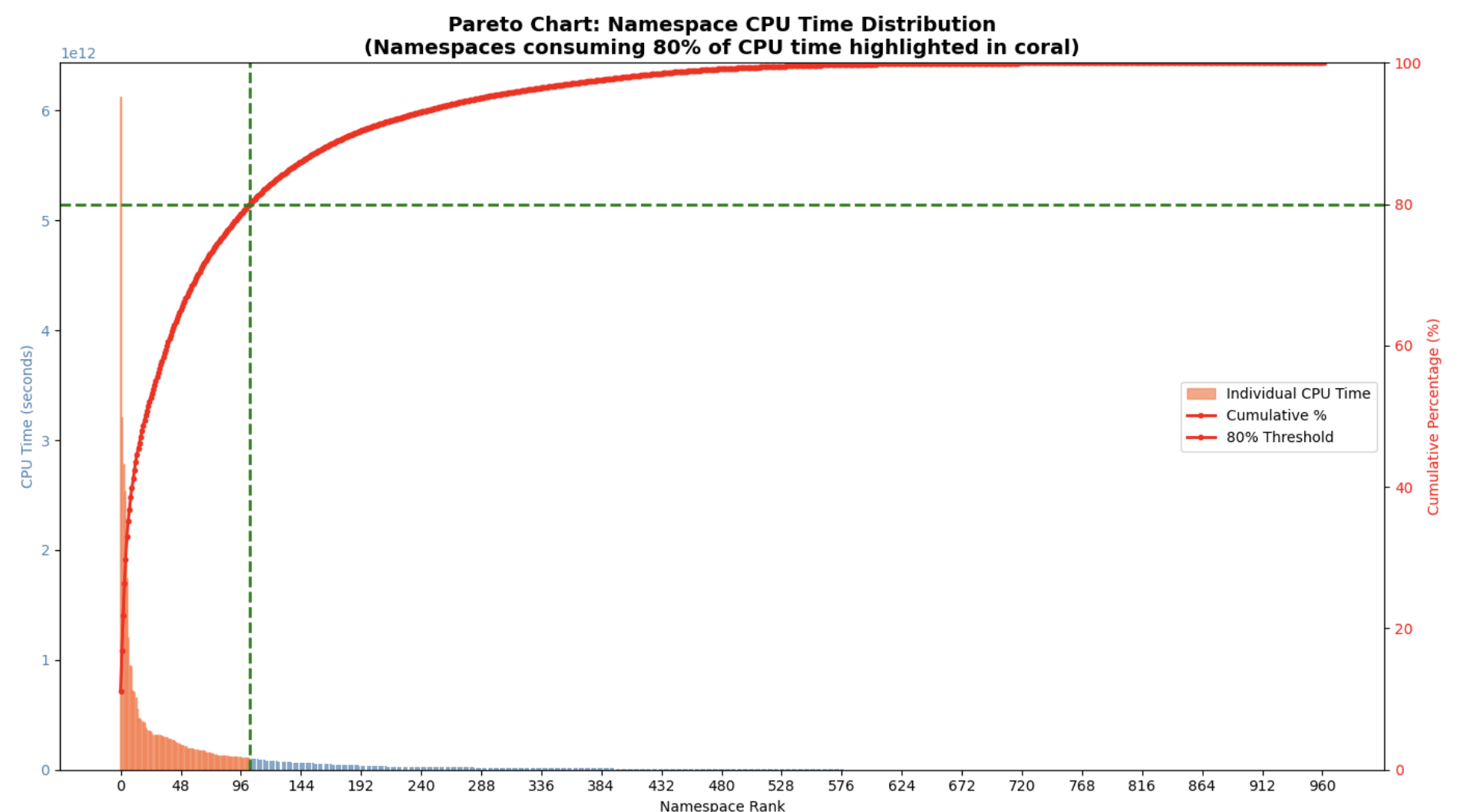
Paretův diagram ověřuje hypotézu 80/20. Ukazuje, že 103 namespaců (z 962, tj. 10,7 %) konzumuje 80 % celkového CPU času. Střední hodnota CPU času pro namespacy je 667,8 tis. CPU dní, medián 64 tisíc CPU dní a maximální hodnota 70,9 mil. CPU dní. TOP 10 namespaces propočítalo 255,86 milionů CPU dní (39,8 %).
V Kubernetes jsou k dispozici individuální účty a projektové účty, přičemž projekt může získat více výpočetních zdrojů.

Projektové účty
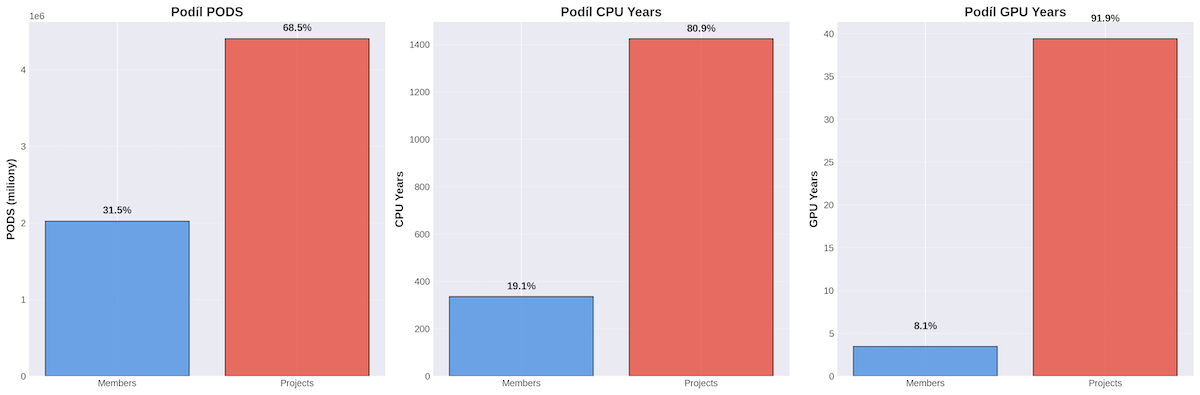
106 projektů v roce 2025 propočítalo 81% celkového CPU času v Kubernetes, tj. 1 419 CPU let a 92% celkového GPU času, tj. 39,4 GPU let. Zbytek připadl na osobní účty.
- Počet projektů: 106
- Počet podů: 4,3 milionů (68% z celkového propočítaného času)
- Celkový CPU čas: 1 419 let (81% z celkového propočítaného času 1 760 CPU let)
- Celkový GPU čas: 39,37 let (92% z celkového propočítaného času)
- Průměrný CPU čas na projekt: 13,39 CPU let
Rozdělení podů, CPU času a GPU času mezi individuální uživatele a projekty.
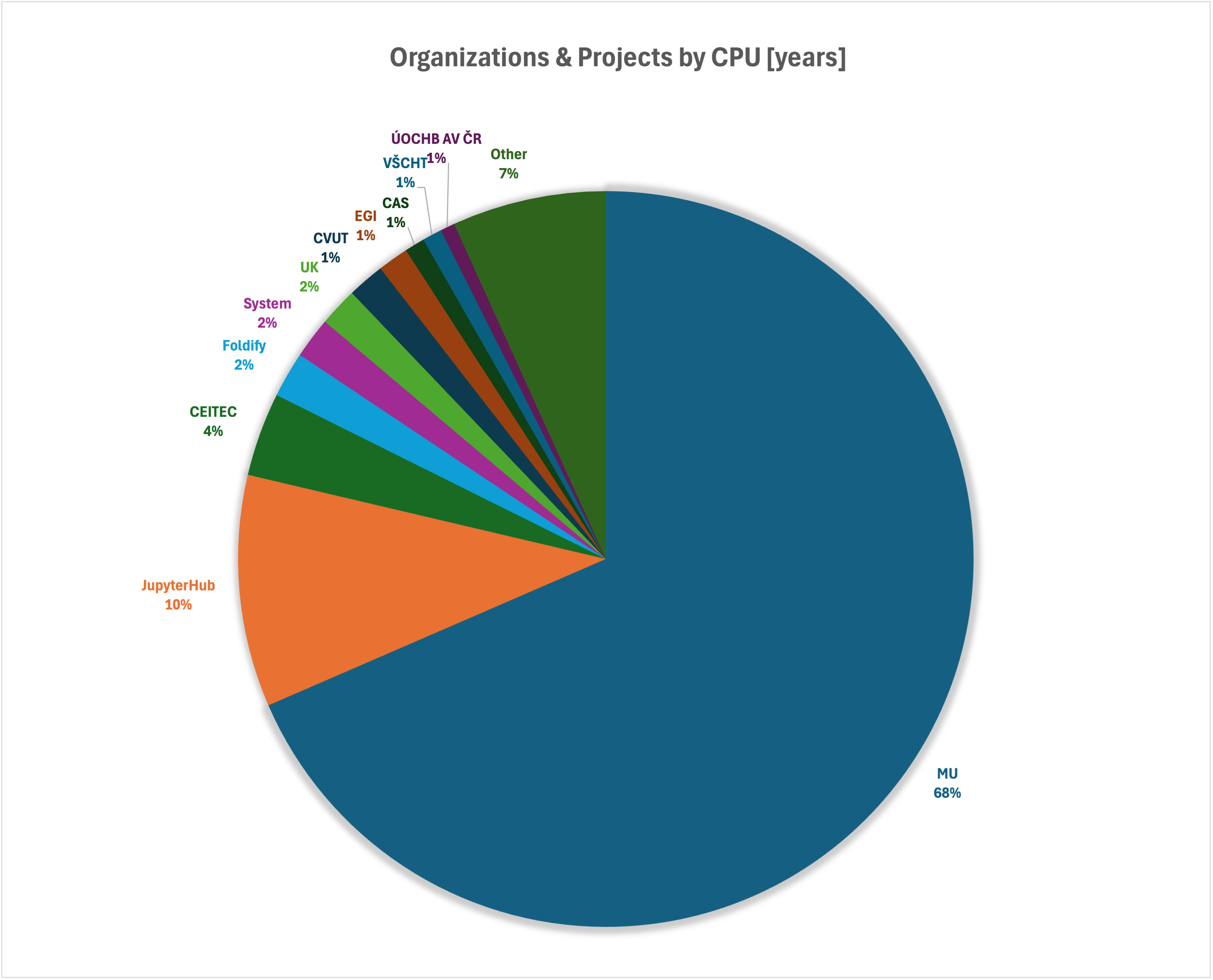
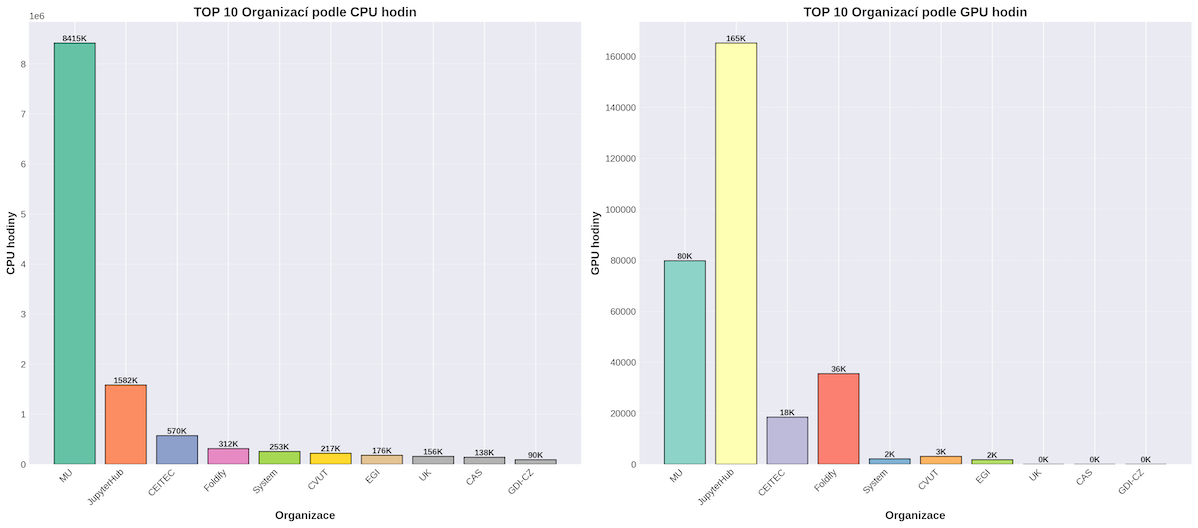
TOP 10 organizací s projektem v Kubernetes podle propočítaného CPU a GPU času.
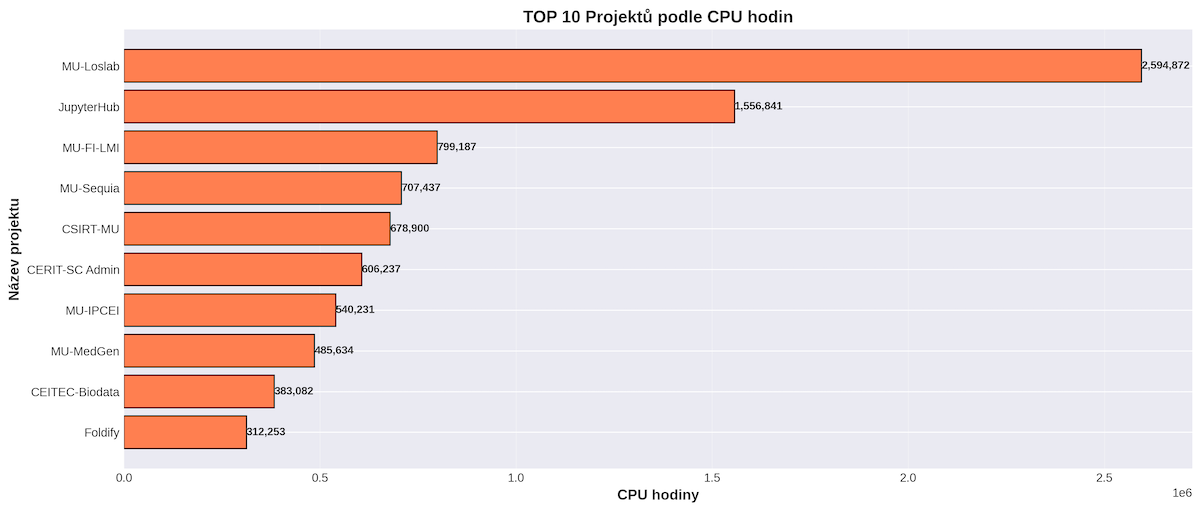
TOP 10 projektů podle propočítaného CPU času.
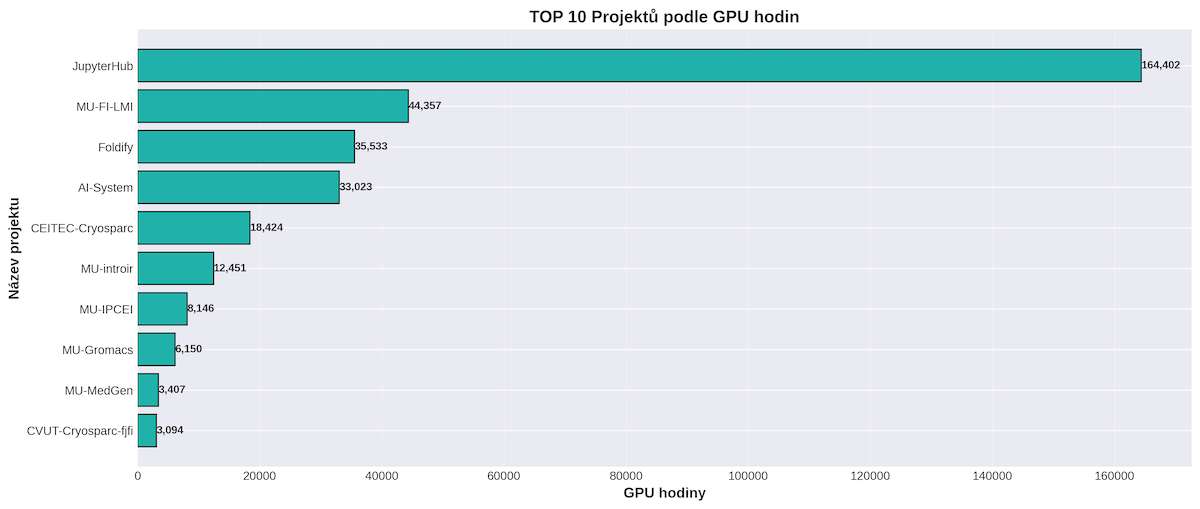
TOP 10 projektů podle propočítaného GPU času.
Individuální uživatelské účty
265 uživatelů spustilo v roce 2025 pod svým účtem alespoň jeden pod, a společně propočítali 19% celkového CPU času, tj. 336,49 CPU let a 8% celkového GPU času, tj. 1,27 GPU let.
- Počet uživatelů (alespoň 1 pod): 265
- Počet podů: 2 020 689 (32% z celkového propočítaného času)
- Celkový CPU čas: 336,34 CPU let (19% z celkového propočítaného času)
- Celkový GPU čas: 3,47 GPU let (8% z celkového propočítaného času)
- Průměrný propočítaný CPU čas na uživatele: 1,27 let
Využití významných samostatných aplikací běžících v Kubernetes
Foldify
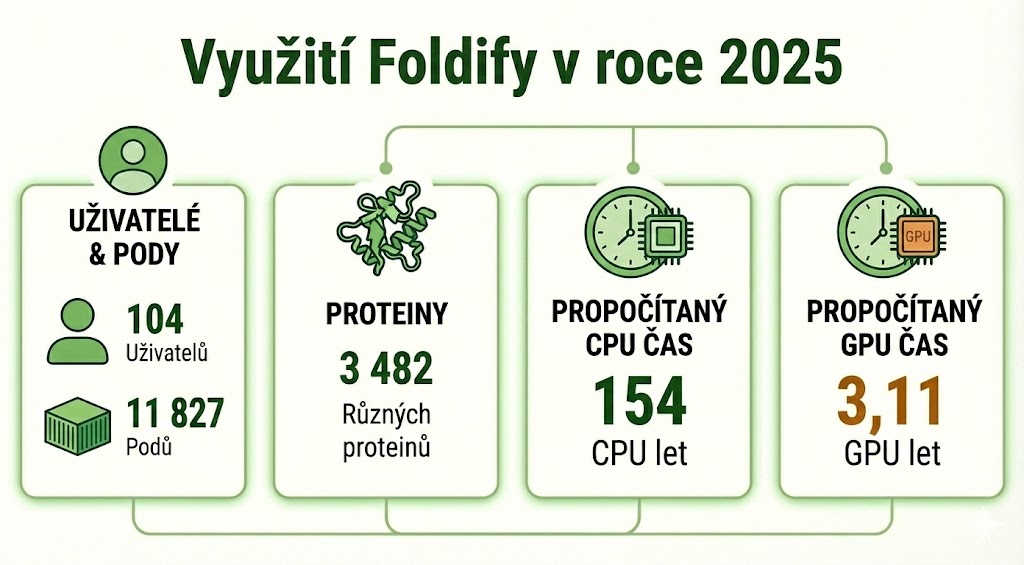
Webovou grafickou službu Foldify, která sdružuje nástroje jako Alphafold, ColabFold, Omegafold, ESMFold využilo 104 uživatelů, kteří s její pomocí spočítali 3 482 různých proteinů a propočítali tím 154 CPU let a 3,11 GPU let.
Jupyter
Webovou službu JupyterHub s JupyterNotebooky využilo 273 uživatelů z 29 organizací. Data pocházejí pouze z ukončených podů k poslednímu dni v roce. Uživatelé propočítali 178 CPU let a 19 GPU let ve 9 534 podech.

Jupyter: TOP 15 organizací podle počtu propočítaného CPU a GPU času a počtu uživatelů z dané organizace:
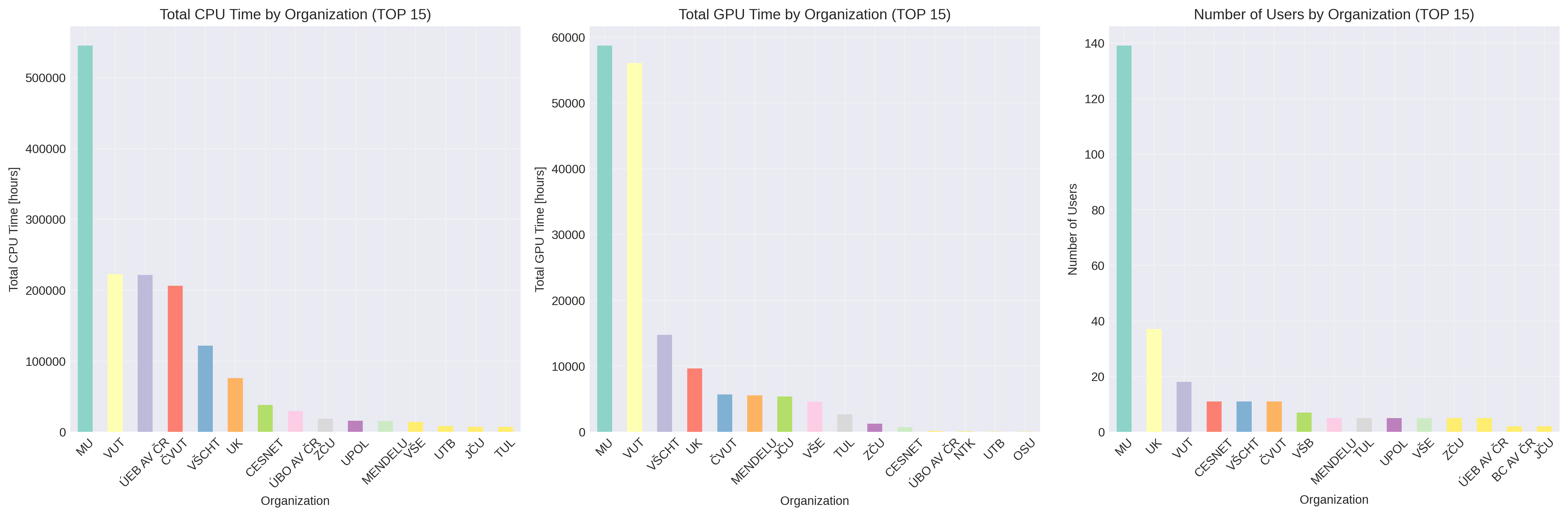
Jupyter: Distribuce CPU a GPU času mezi organizacemi.
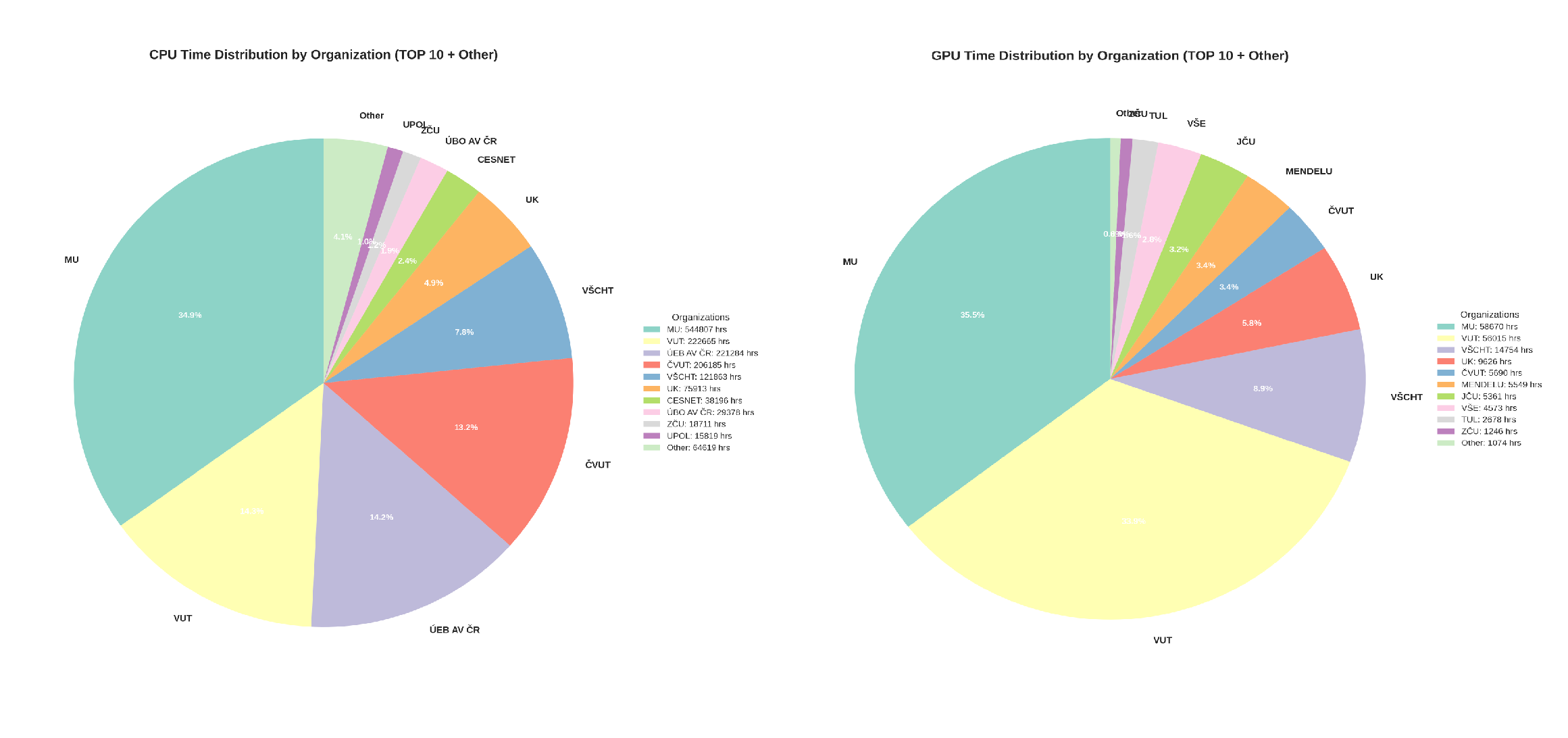
Počet běžících Jupyter Notebooků v jednotlivých dnech roku 2025.
Distribuce CPU a GPU času, podů a organizací v Jupyter Noteboocích.
A nyní se podíváme na dobu běhu notebooků, zajímá nás skutečná doba běhu očištěná od množství využitých CPU jader. Odečetli jsme servisní notebooky, které iniciují spouštění dalších úloh:
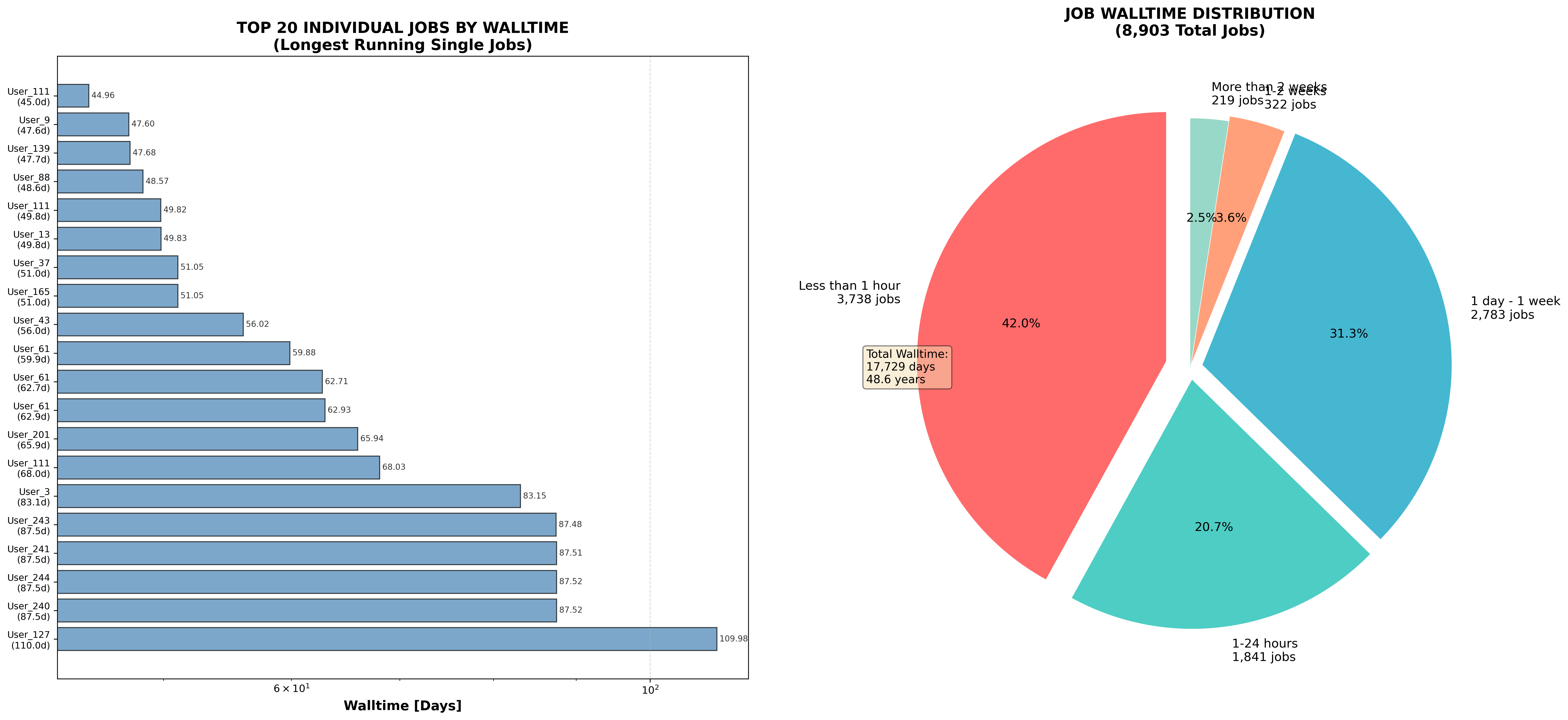
- Počet uvažovaných notebooků: 8 903
- Počet uživatelských namespaců: 273
- Celková doba běhu všech notebooků: 17 729,14 dní (48,6 let)
- Průměrná doba běhu notebooku: 1,99 dní (47.79 hodin)
- Median: 0.1430 dní (3.43 hodin)
- Nejdelší doba běhu: 109.98 dní
- Nejkratší doba běhu: 0.000012 dní
Nejdelší aktivní notebook běžel 110 dní. Na levém grafu je TOP 20 uživatelů podle délky běhu notebooku. Pravý graf ukazuje podíl úloh podle délky běhu notebooku:
- <1 hodinu: 3 738 notebooků (42.0%)
- 1 až 24 hodin: 1 841 notebooků (20.7%)
- 1 den až 1 týden: 2 783 notebooků (31.3%)
- 1 až 2 týdny: 322 notebooků (3.6%)
- > 2 týdny: 219 notebooků (2.5%)
Pro následující grafy počítáme celkovou dobu běhu všech notebooků spuštěných uživatelem.
Vlevo nahoře graf obrazující vztah mezi počtem spuštěných úloh a celkovou dobou běhu notebooků jednotlivých uživatelů.
Vpravo nahoře Paretův diagram 80/20 zobrazující že TOP50 uživatelů zkonzumuje 80 % celkové doby běhu všech jupyter notebooků (14 269,98 dní z celkových 17 729 dní). Zobrazujeme jen prvních 50 uživatelů. Vlevo dole TOP 20 uživatelů podle celkové doby běhu všech svých notebooků. Vpravo dole podíl uživatelů na celkovém walltime:

Níže uvádíme shrnutí analýzy vytížení CPU a GPU v rámci jupyterovských namespaců. Data zohledňují povolený overcommitting (CPU čas je normalizován faktorem 3).
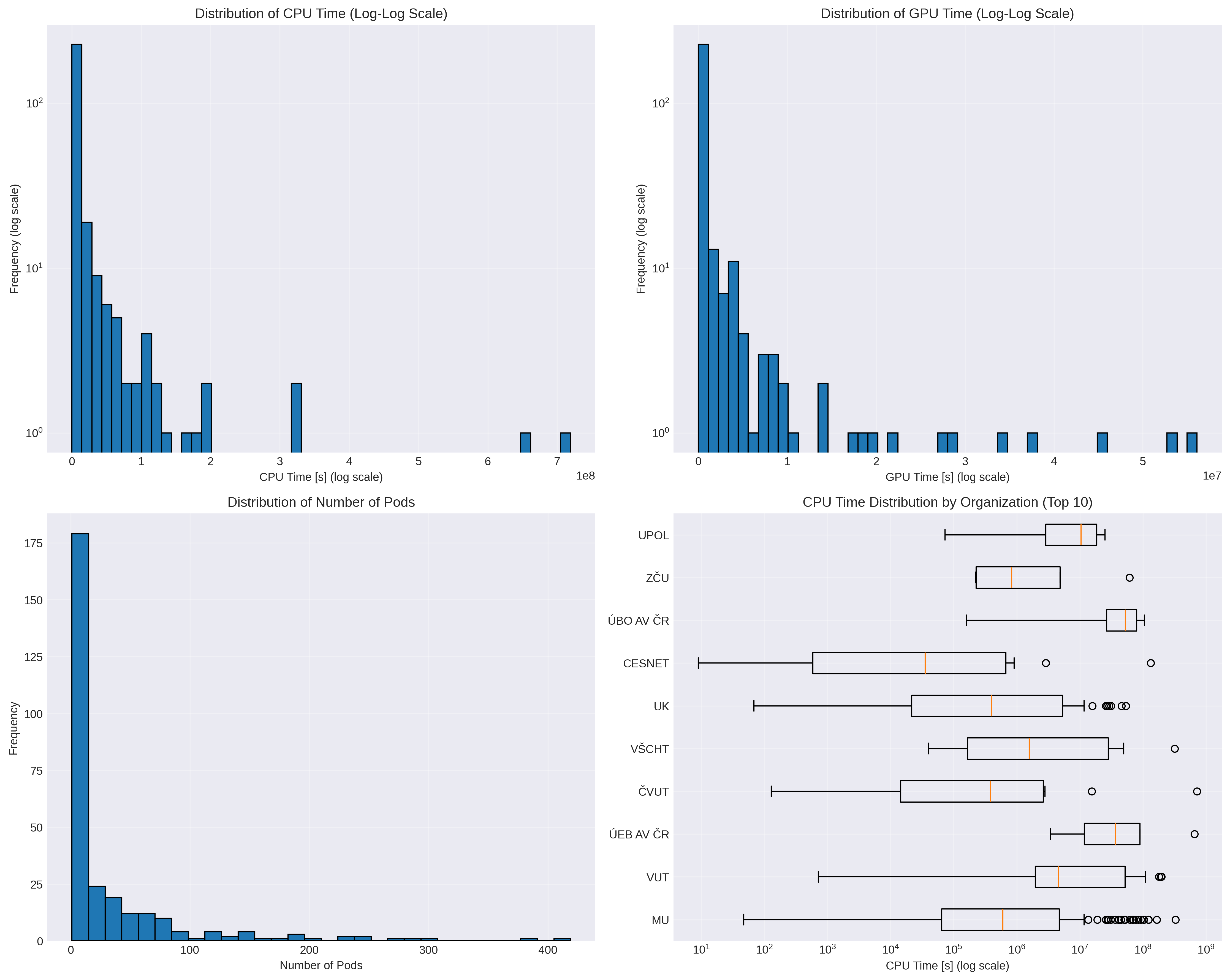
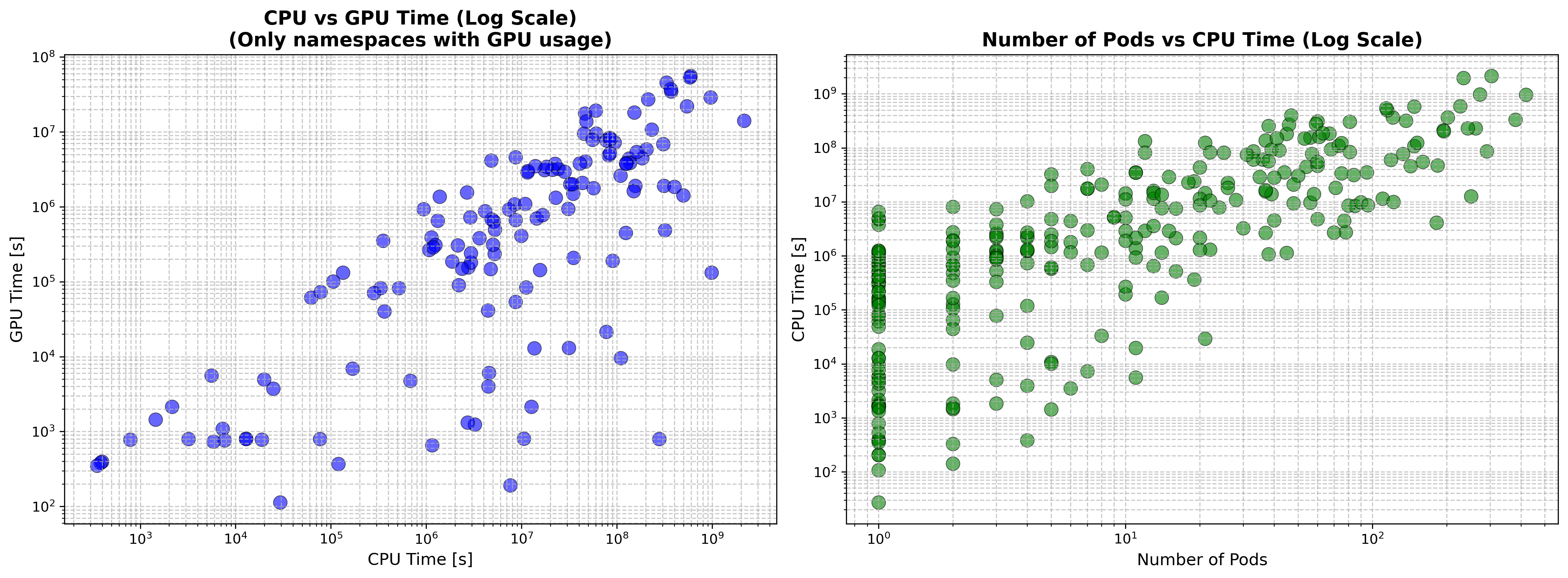
Na levém grafu CPU vs. GPU čas: Mezi těmito metrikami existuje středně pozitivní korelace (0,47). Analýza zahrnuje 140 namespaců, které aktivně využívaly GPU. Započítány jsou pouze ty, které požadovaly i GPU.
Druhý graf počet podů vs. CPU čas: Zde je patrná výrazná pozitivní korelace (0,64) napříč všemi 289 namespacy. Ukazuje vztah mezi počtem podů a CPU časem přes všech 289 namespaců.
- Normalizovaný CPU čas (namespace): 27 s až 2,15 mld. s (tj. 68,424 CPU let), střední hodnota 1,88 CPU let
- Normalizovaný GPU čas (namespace): 0 až 56,097 mil. s (tj. 1,78 GPU let), střední hodnota 23,9 GPU dní
- Počet podů na namespace: 0 až 419, střední hodnota 34,32
SensitiveCloud

V SensitiveCloudu bylo v roce 2025 v provozu 1 112 CPU jader a 40 GPU akcelerátorů. Služeb využilo 23 projektů z 5 organizací.
- Počet projektů využívajících GPU: 5
- Počet podů: 37 873
- Celkový CPU čas: 657 CPU let
- Celkový GPU čas: 35 GPU let
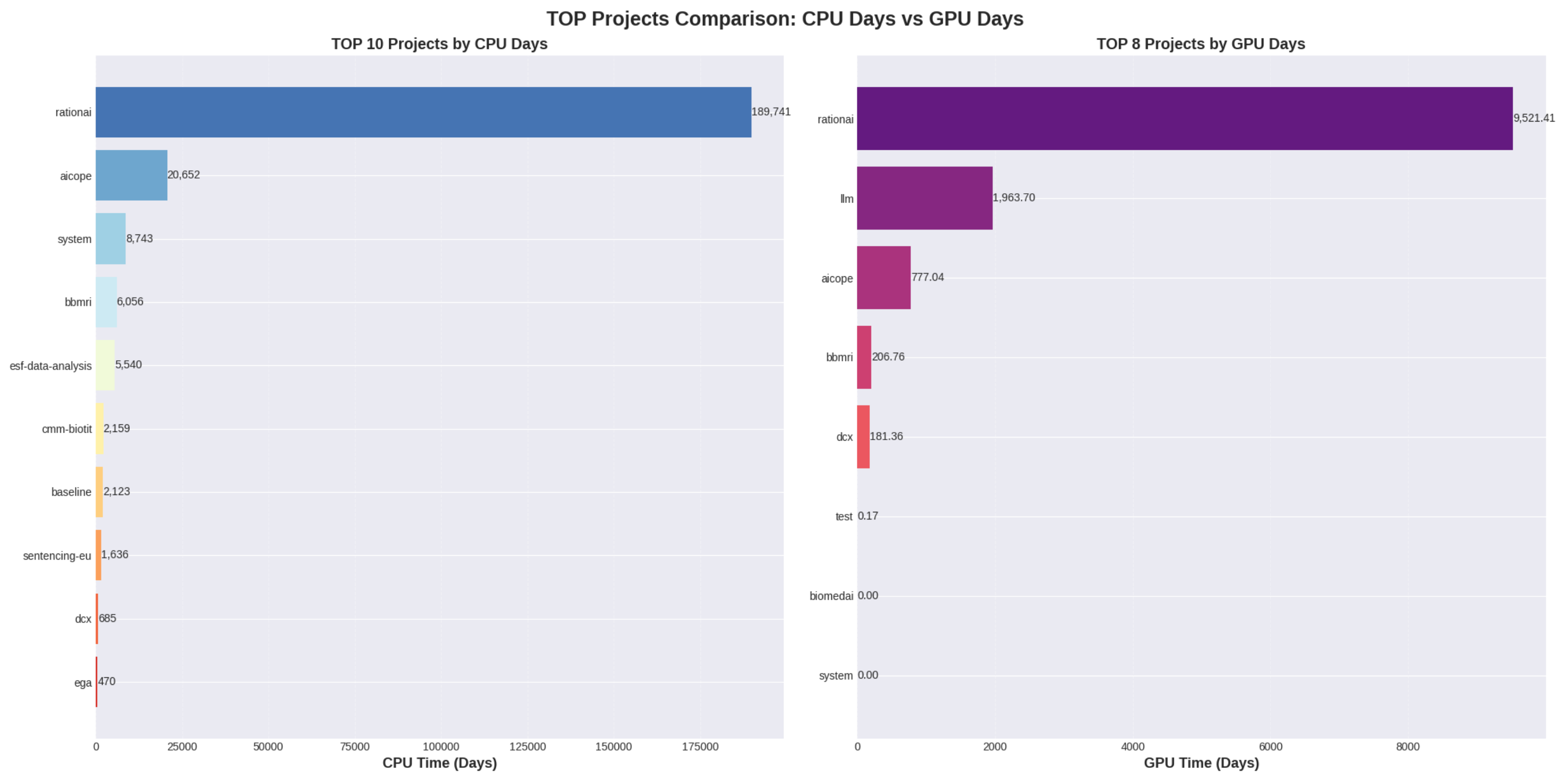
Nejvíce CPU času zkonzumoval projekt rationai (519 CPU let, 79% celkového propočítaného času), na druhém místě byl projekt aicope. Nejvíce GPU času zkonzumoval rovněž projekt rationai (26 GPU let, 75% celkového propočítaného času), na druhém místě byl projekt llm (provoz jazykových modelů).
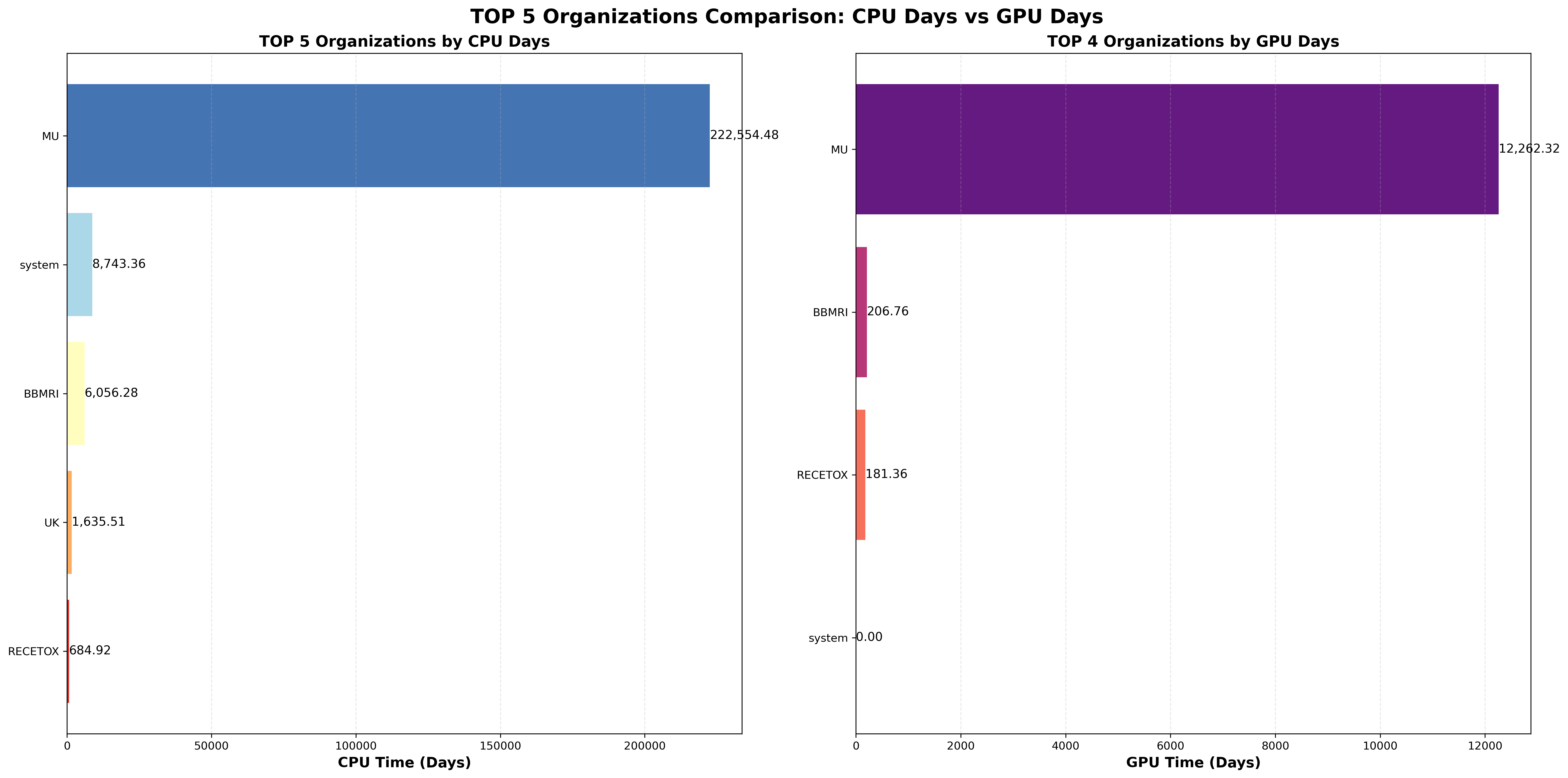
Nejaktivnější jsou uživatelé hlásící se k Masarykově univerzitě. Ta propočítala 610 CPU let, 93% celkového propočítaného času a 33 GPU let, 96% celkového propočítaného času. Projekty hlásící se k RECETOX a případně BBMRI spadají též pod MU, takže procento využití CPU a GPU času organizací MU by bylo, po započítání těchto dvou velkých projektů, ještě vyšší.
Levý graf ukazuje distribuci CPU času v jednotlivých podech. Z grafu je zřejmé, že projekt rationai má nejvíce podů s největším propočítaným časem. Pravý graf ilustruje podíl propočítaného času podle jednotlivých organizací.
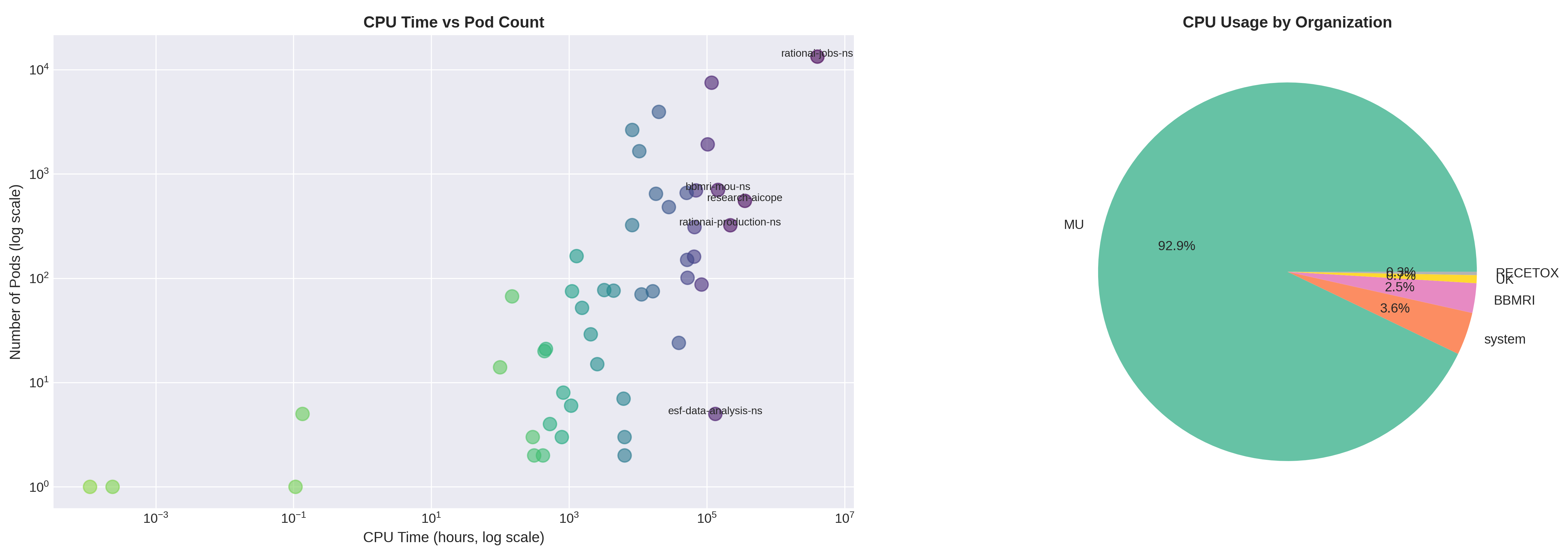
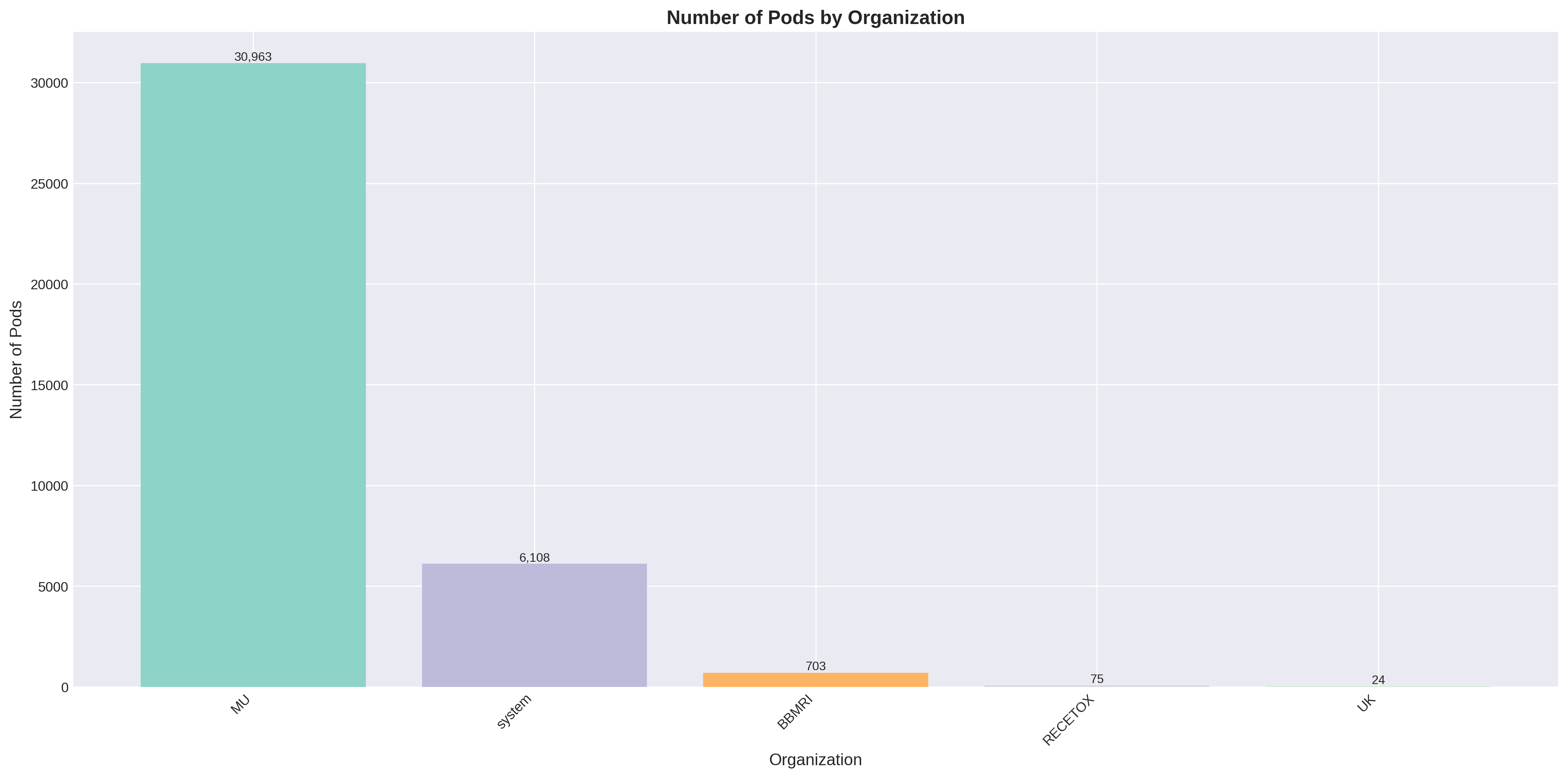
Počet podů spuštěných projekty z jednotlivých organizací. Opět vede Masarykova univerzita s 30 963 pody, což představuje 82% ze všech spuštěných podů.
Chat AI + LLM

Centrum CERIT-SC spustilo v únoru 2025 službu pro inferenci velkých jazykových modelů (LLM). Za uplynulý rok prošla tato platforma zásadní transformací. Začínala s malými modely o velikosti 70 miliard parametrů (cca 40 GB vah). Nyní je k dispozici několik modelů blížících se hranici 700 miliard parametrů a jeden velký model s 1 000 miliardami (1T) parametrů, vše na vlastním hardwaru NVIDIA DGX B200 a B300.
Kolem samotné inference jsme vybudovali ucelený ekosystém AI služeb, který zahrnuje např.:
- ChatAI, API
- Podpora agentů skrze platformu n8n.
- Podpora pro VS Code, terminálová prostředí a Jupyter Notebooky.
- Provozování MCP serverů (Model Context Protocol) pro efektivní propojování modelů s datovými zdroji.
- Inteligentní vyhledávání a překlady v dokumentacích.
Od spuštění služby se k AI chatu přihlásilo téměř 1000 uživatelů. Nicméně podrobnější statistiky využití jazykových modelů jsou sesbírané pouze za 1 měsíc. Podrobná anonymizovaná telemetrická data se sbírají od prosince 2025 až díky napojení na LightLLM. Data slouží k detailnější analýze využití a optimalizaci nastavení infrastruktury.
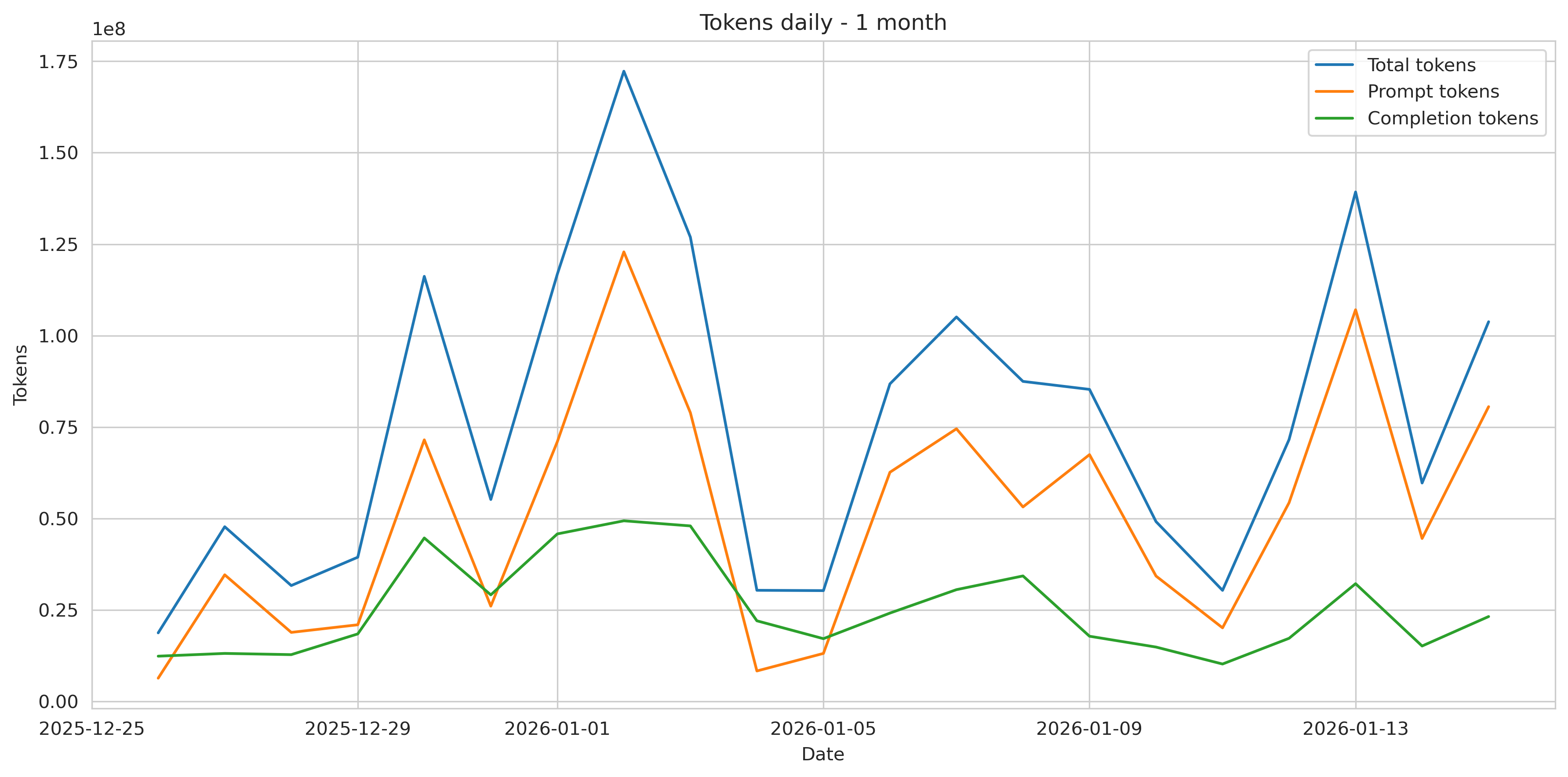
Denní využití tokenů během posledního měsíce roku.
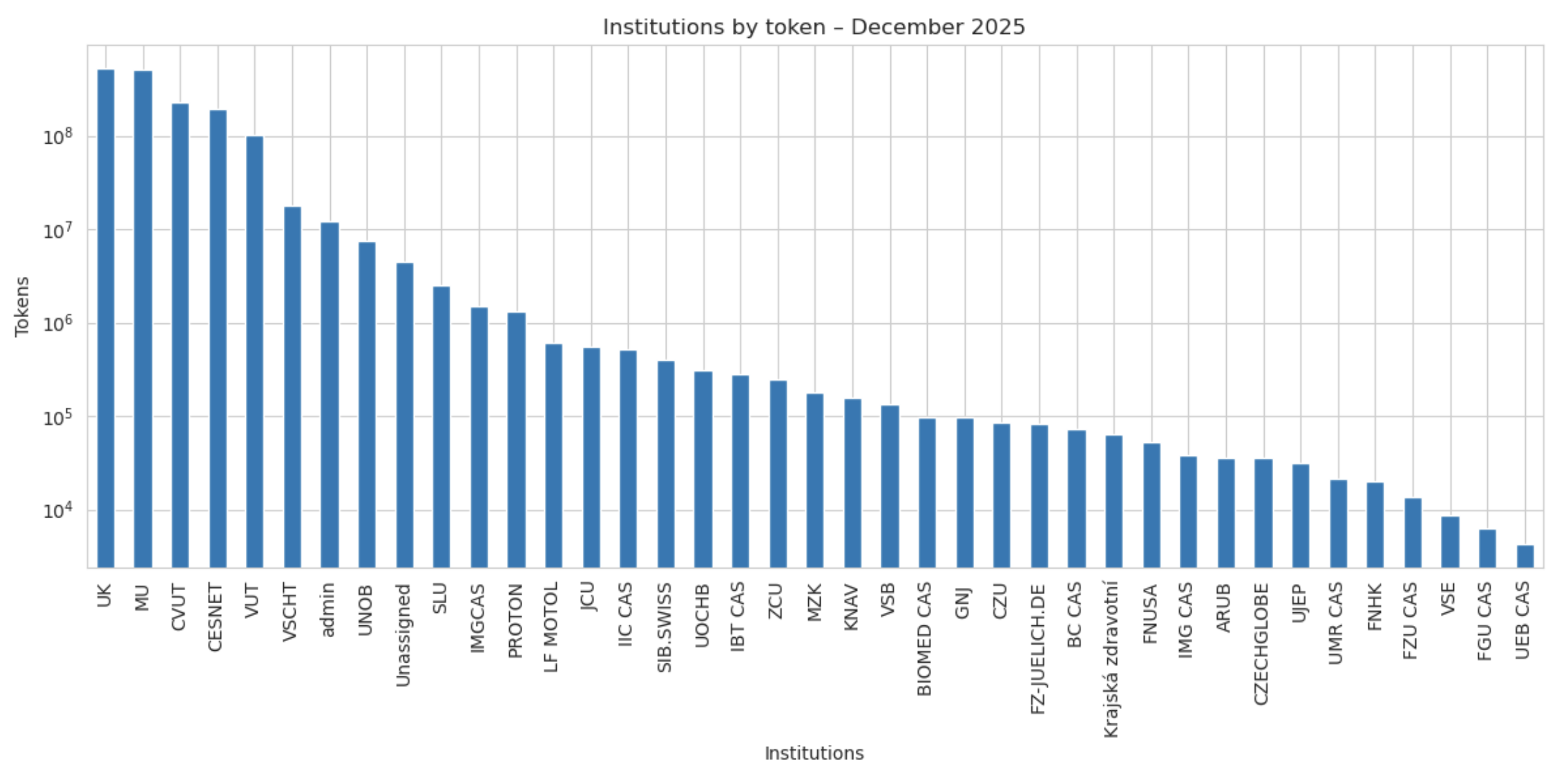
Jazykové modely v prosinci využívalo 233 uživatelů z 39 institucí. Nejaktivnější byli uživatelé z Karlovy univerzity s 517 mil. tokenů (32%), následovala Masarykova univerzita s 512 mil. tokenů (31%), ČVUT 228 mil. tokenů (14%), CESNET 192 mil. tokenů (11%) a VUT 102 mil. tokenů (10%)
Využití počtu tokenů institucemi v podílovém grafu. Tři nejaktivnější organizace využívají více než 3/4 všech spotřebovaných tokenů. Pravý graf ukazuje spider/radar graf pro TOP 6 organizací. Každá organizace má svoji barvu a hodnoty na pěti osách tvoří uzavřený pavoukový útvar. Čím větší plocha a rozložení úseček, tím vyšší spotřeba v dané dimenzi. Sleduje se počet uživatelů, počet tokenů, průměrný počet tokenů na uživatele organizace, počet dotazů a jejich průměr na uživatele organizace.
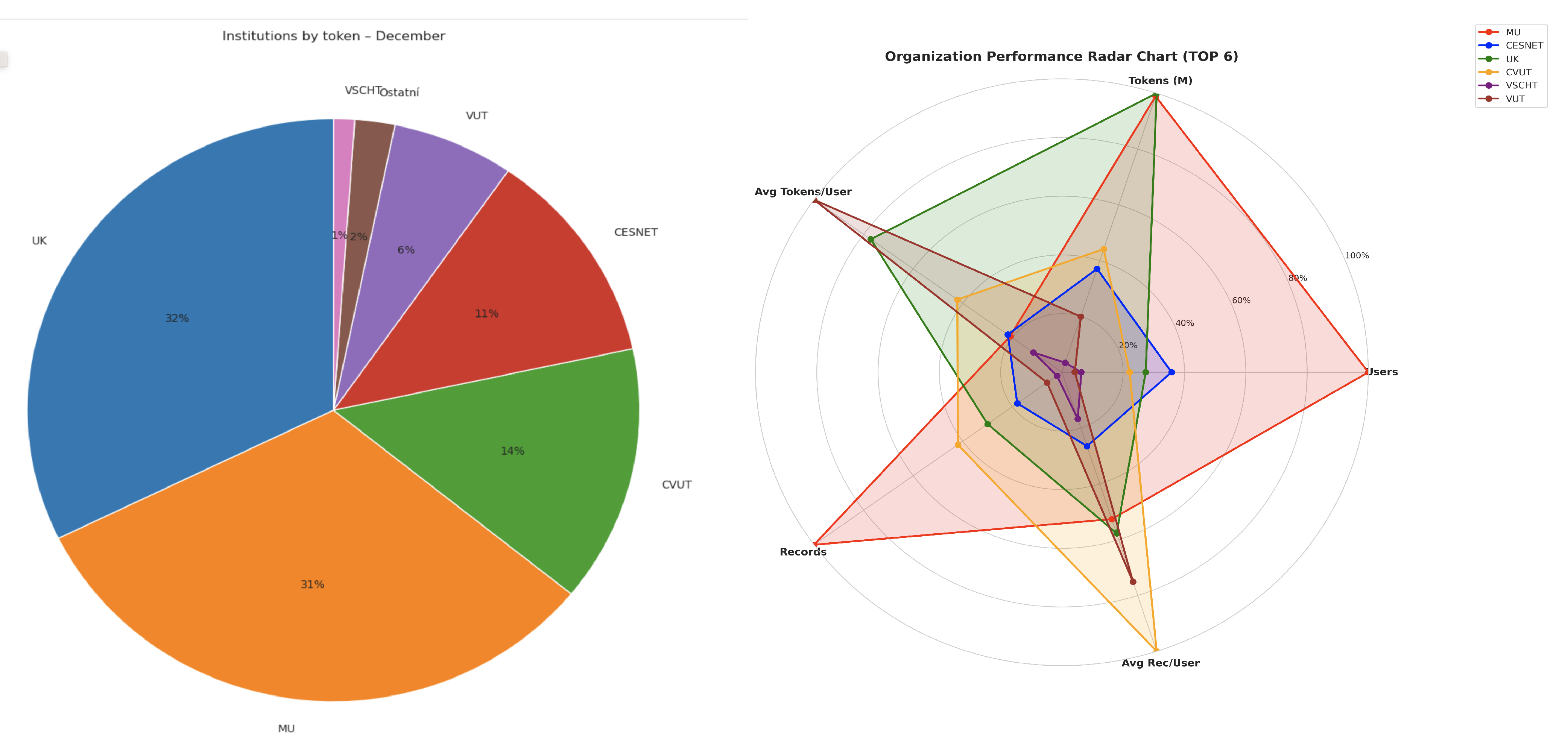
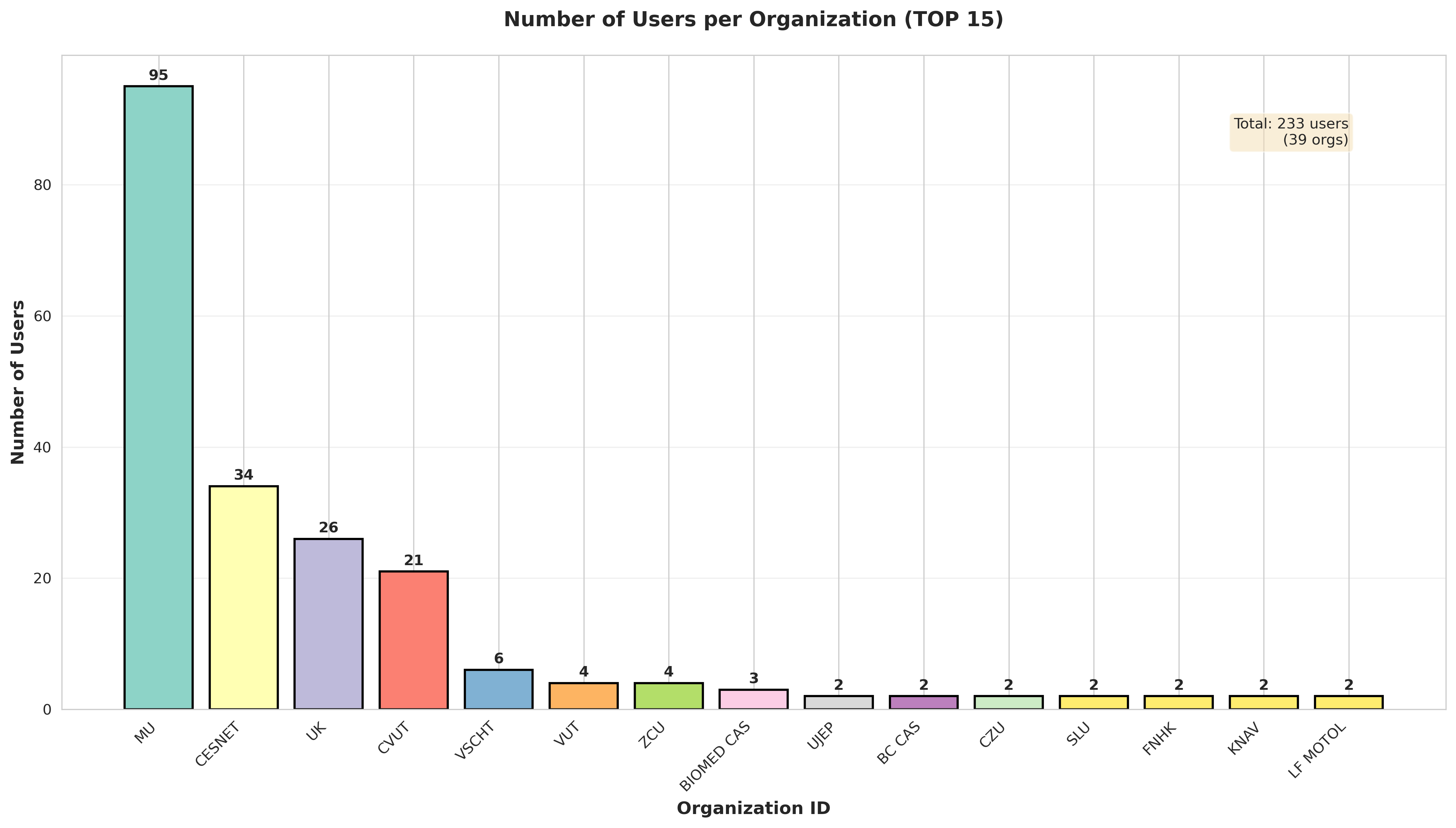
Počet uživatelů z TOP 15 organizací. Mezi uživateli je nejvíce zastoupená Masarykova univerzita (95 uživatelů), CESNET (34 uživatelů), Univerzita Karlova (26 uživatelů) a ČVUT (21 uživatelů).
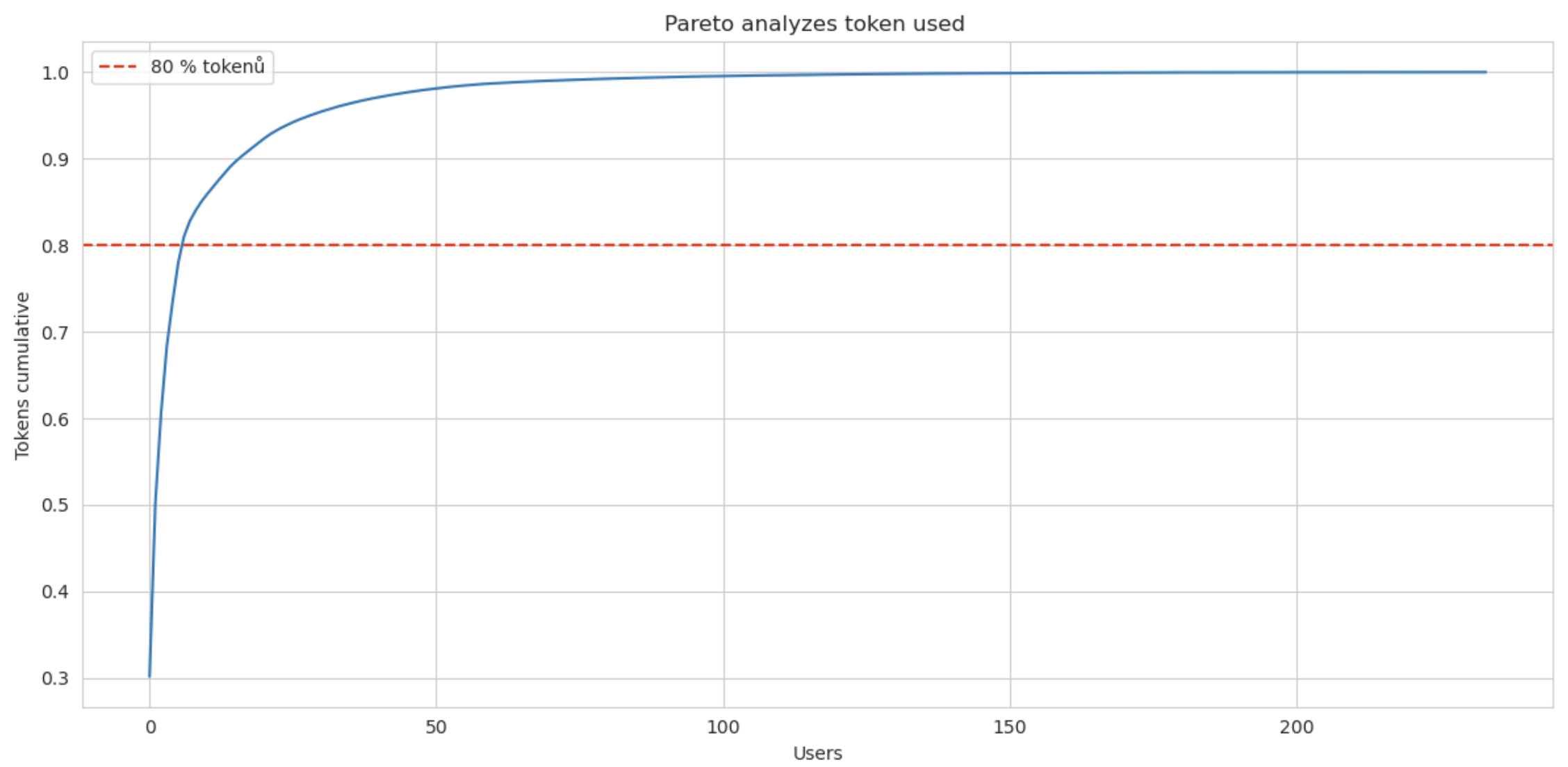
Pareto analýza. TOP 6 uživatelů spotřebovalo 80 % tokenů. Celkově uživatelé během jediného měsíce spotřebovali 1,6 mld. tokenů.
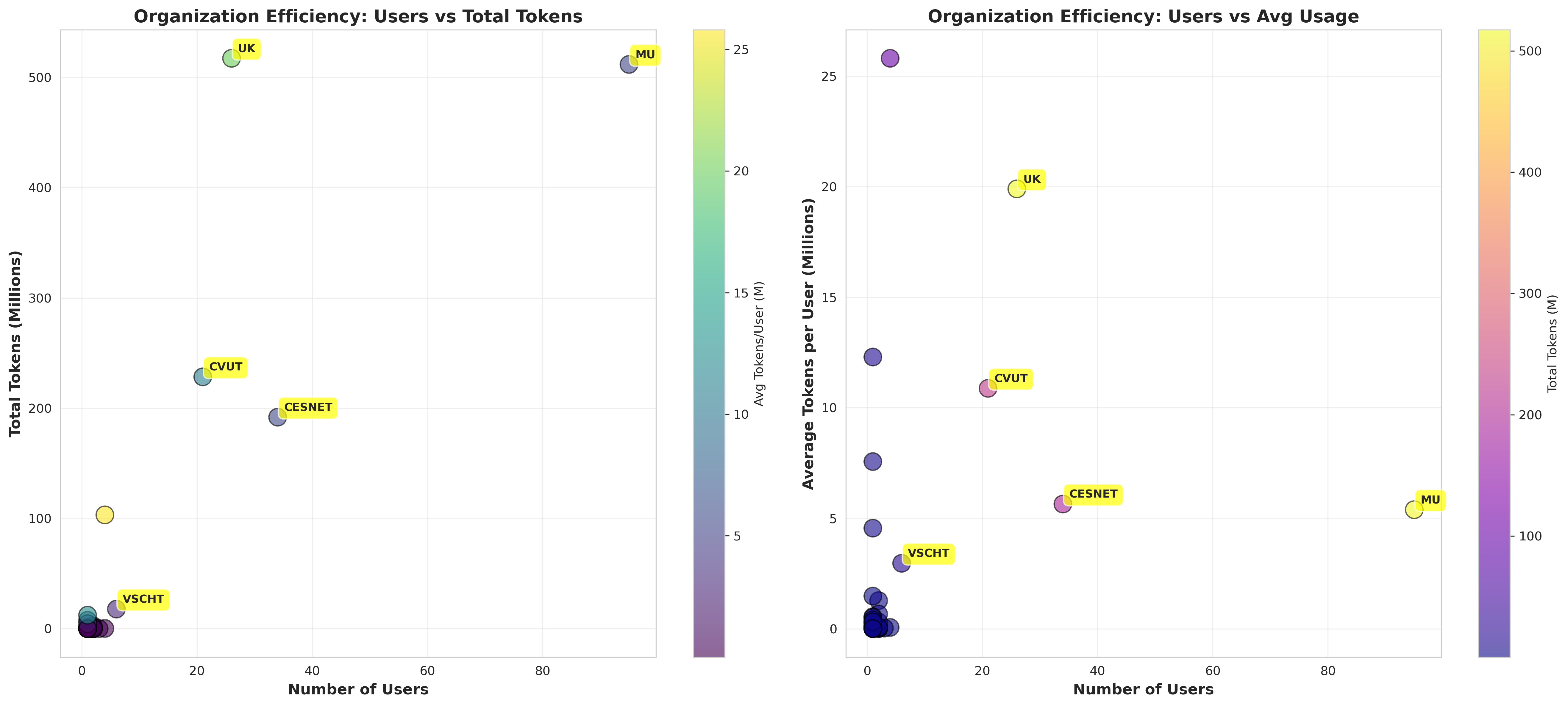
Rozptylové grafy (scatter plots) hodnotí efektivitu využití. Celkový počet tokenů zobrazuje vztah mezi počtem uživatelů organizace a spotřebou tokenů. Druhý graf ukazuje průměrný počet tokenů spotřebovaný v rámci organizace.
OpenStack Cloud

V roce 2025 MetaCentrum (OpenStack) Cloud provozoval 9 670 CPU jader a 84 GPU, z toho 7 238 CPU jader a 84 GPU v Brně a 2 432 CPU jader v Ostravě.
- Bylo propočítáno celkem 4 235 CPU let (v režimu over-commiting, kdy jedno fyzické jádro hostuje více virtuálních) a 23 GPU let v 81 tis. instancích
- V cloudu jsou stroje rozlišeny podle určení nebo vlastníků: meta, cerit-sc, elixir, mu, recetox, csirt.
- Zdroje jsou nabízené dvěma způsoby: osobní využití, s omezením počtu a velikosti běžících instancí, a projektové využití.
V roce 2025 měl cloud 7 239 jader, které reprezentují kapacitu 63 410 720 CPU hodin. Využití CPU bylo 88 231 684 CPU hodin, tj. 139 % kapacity. CPU kapacita cloudu je dána počtem fyzických jader CPU a jejich promítnutím do časové roviny, kdy předpokládáme využití 24h po celý rok. Využití cloudu je dáno měřením alokace virtuálních jader CPU. V případě, kdy využití cloudu převyšuje jeho kapacitu, dochází k tzv. overcommitu, kdy jedno fyzické jádro poslouží k vytvoření několika virtuálních jader.
V roce 2025 byla kapacita paměti RAM 145,23 TB, která byla přes rok čerpána 407 628 TB hodin. To odpovídá využití 32 %.
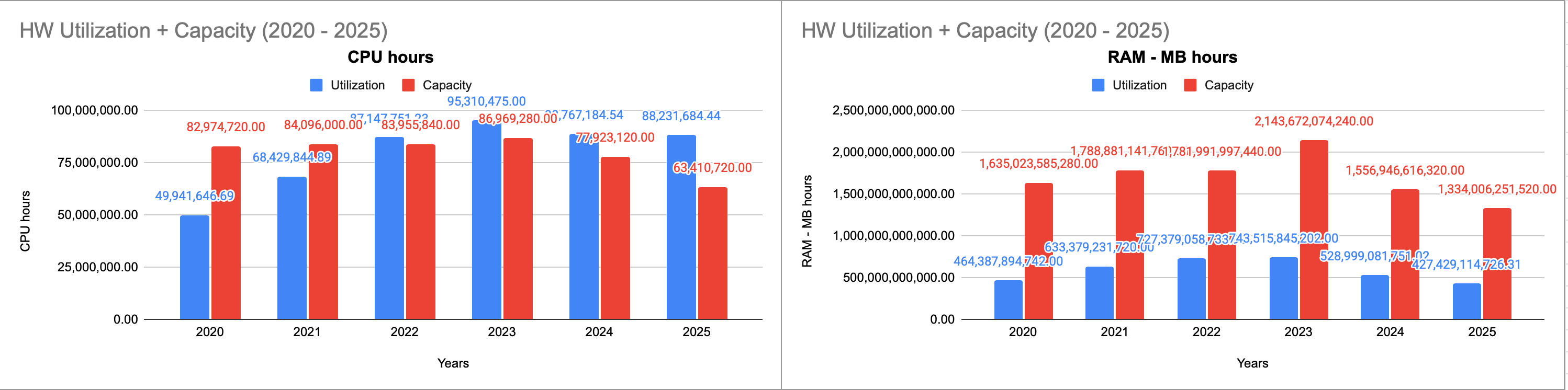
V roce 2025 disponoval cloud grafickými kartami s celkovým počtem 84 jader, což představuje roční kapacitu 738 760 hodin. Skutečné využití dosáhlo téměř 70 %.
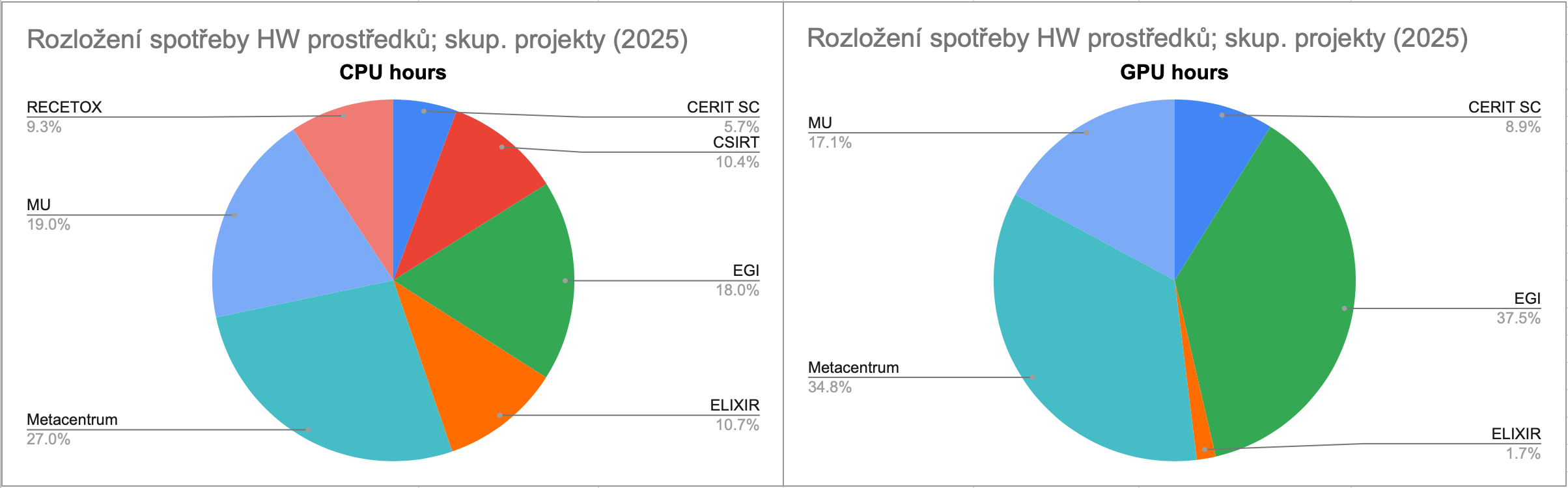
Z hlediska využití CPU bylo nejvíce aktivní Metacentrum. Kromě skupinových projektů provozuje Metacentrum i 94 % všech osobních projektů v cloudu což zvyšuje podíl utilizace zdrojů ve prospěch MetaCentra.
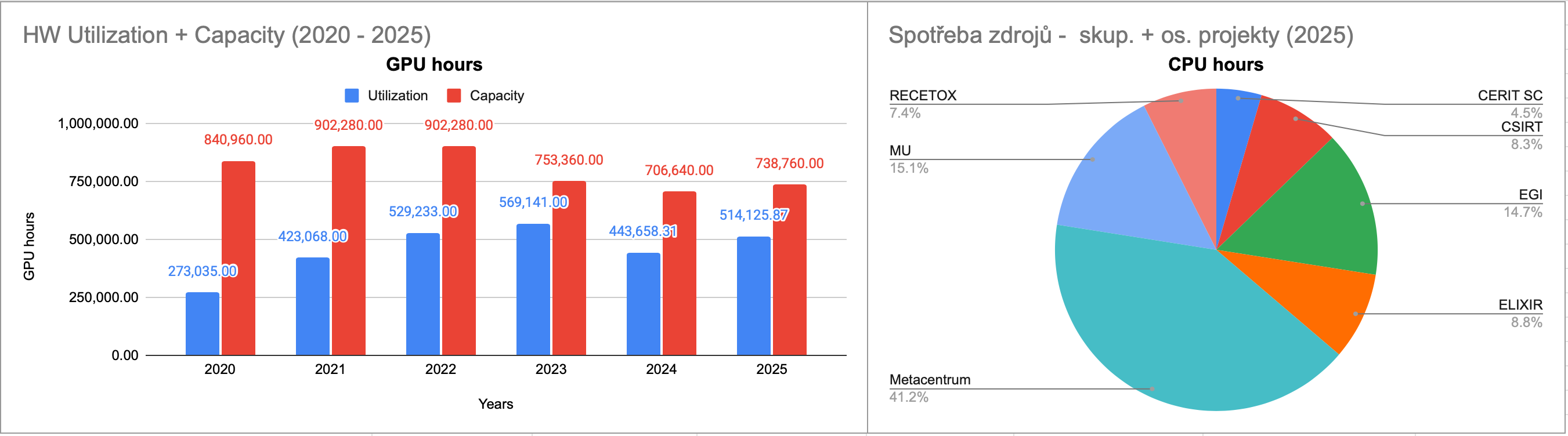
Z hlediska využití CPU zdrojů skupinovými projekty jsou nejvíce aktivní Metacentrum a MU, které dohromady tvoří 46 % celkové spotřeby.
Výkon GPU karet je k dispozici pouze skupinovým projektům. GPU jádra nejvíce využívaly skupinové projekty zákazníka EGI (FedCloud), který v roce 2025 provozoval celkem 70 projektů, a Metacentrum se 172 projekty. Mezi deseti projekty s nejvyšší spotřebou GPU času dominují tyto dva subjekty.
Největší počet skupinových projektů provozovalo v roce 2025 Metacentrum a Masarykova univerzita, dohromady 70 %. Toto koreluje s využitím procesorového času.
Největší podíl na počtu spuštěných virtuálních strojů má EGI, a to zejména díky management/operations projektu "ops".
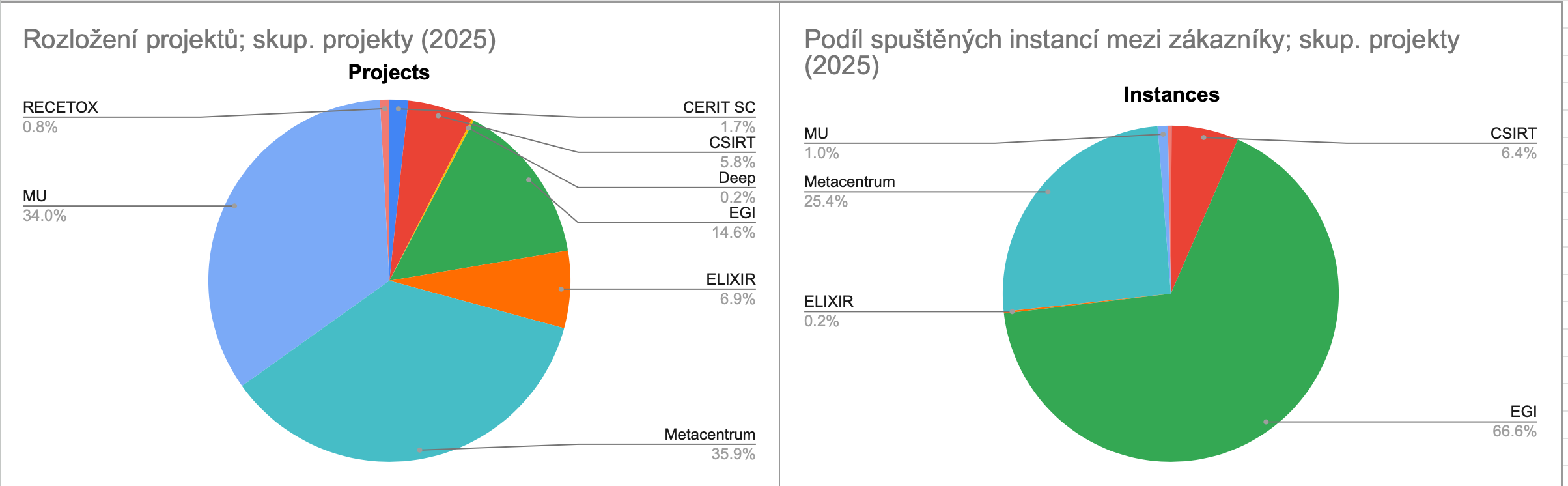
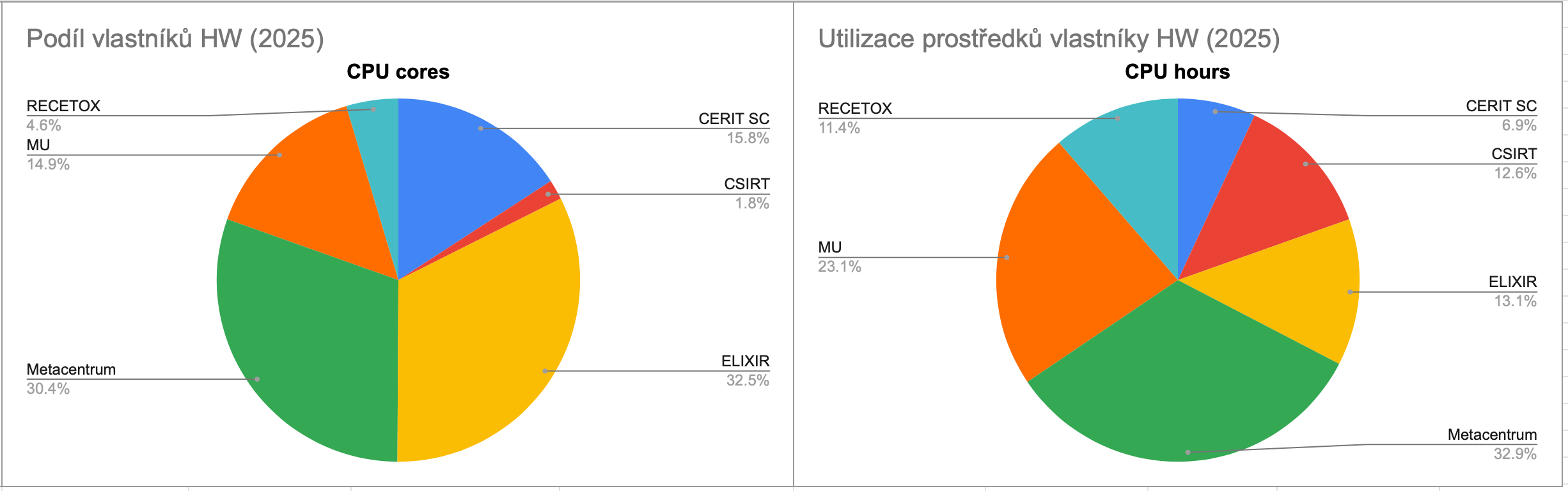
Vlastníci výpočetních zdrojů
Cloud je tvořen desítkami strojů organizovaných do clusterů, které financují různé organizace a kterých jsou vlastníky. Podíl vlastníků dle počtu pořízených CPU jader vyjadřuje následující graf.
Využití CPU času posuzujeme v rovině skupinových projektů a v ideálním případě každá organizace využije CPU čas adekvátně tomu, kolik CPU jader vlastní.
Srovnáním podílu na celkovém množství spotřebovaného času CPU jader (sloupec 2025 CPU hours) a vlastnickém podílu v celkovém objemu clusterů (sloupec 2025 CPU hw - cores) lze posoudit, zda zákazníci využívají CPU čas adekvátně vzhledem ke svému podílu investic do HW.
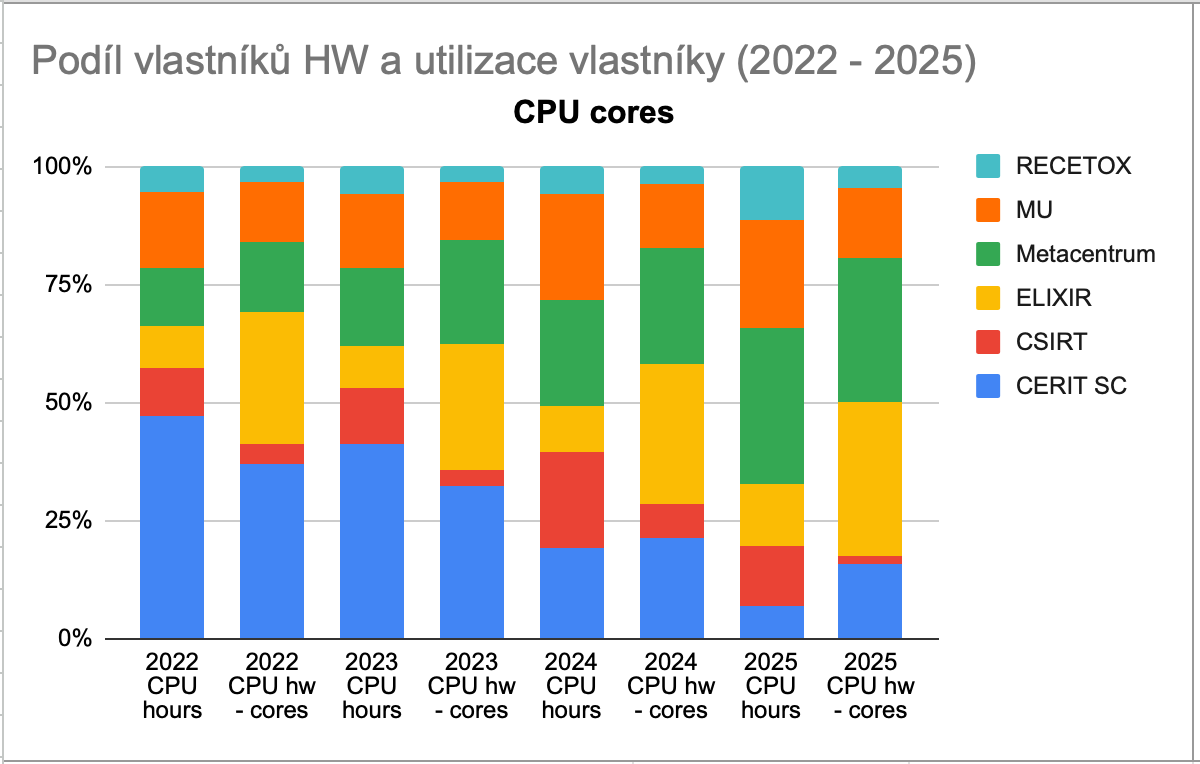
Cloud je tvořen desítkami strojů organizovanými do clusterů, které financují různé organizace. Stroje přispívají k celkové kapacitě výpočetních zdrojů cloudu, měřitelné především počtem CPU jader a velikostí paměti RAM. Vzhledem k důležitosti CPU jader uvádíme podíl vlastnictví pomocí tohoto ukazatele.
Využití CPU času posuzujeme pomocí spotřeby skupinových projektů. V ideálním případě každá organizace využije CPU čas adekvátně tomu, kolik CPU jader vlastní.
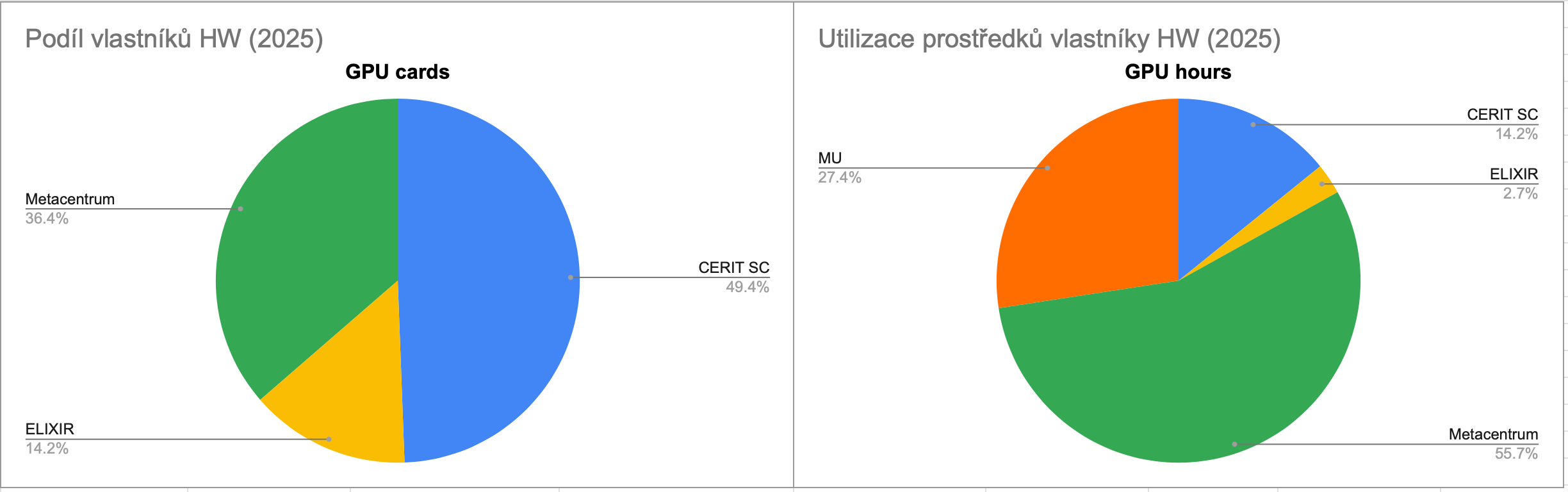
Srovnáním podílu na celkovém množství spotřebovaného času GPU jader (sloupec 2025 GPU hours), a vlastnickém podílu v celkovém objemu GPU karet (sloupec 2025 GPU hw - cores), lze posoudit, zda zákazníci využívají GPU čas karet adekvátně, vzhledem ke svému podílu investic do tohoto typu HW.
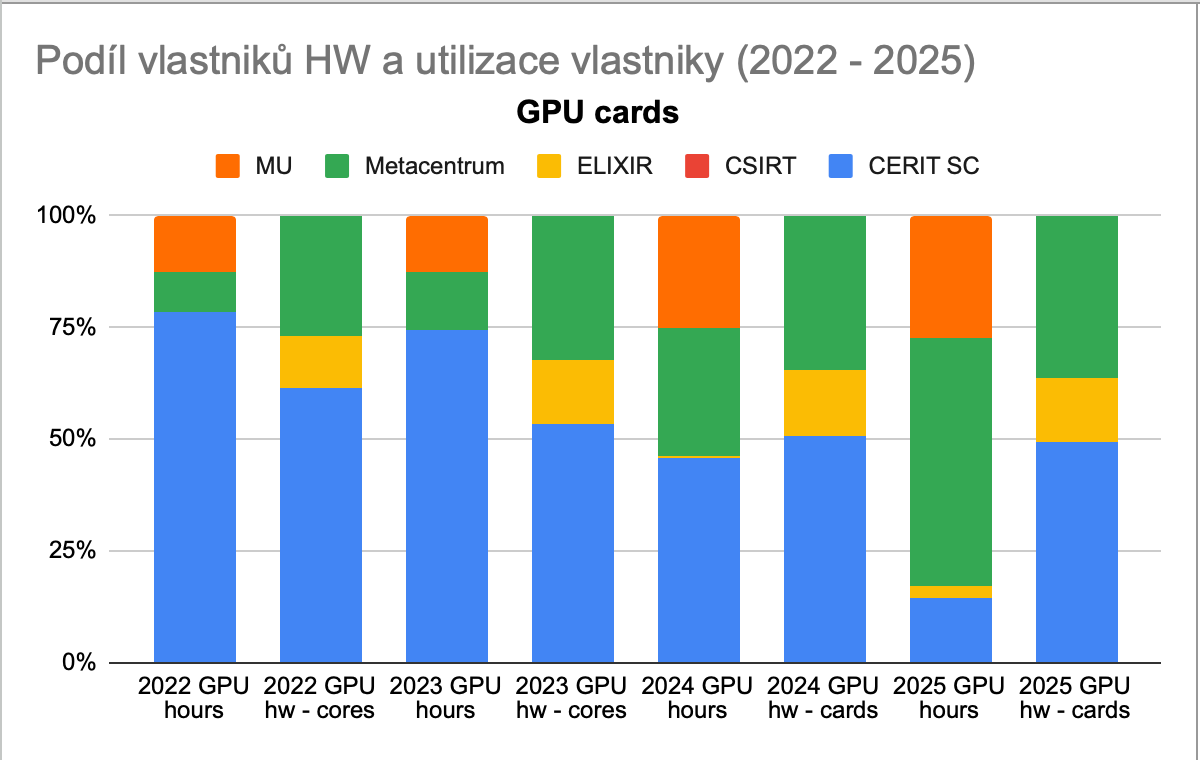
I v případě GPU kapacity cloudu evidujeme podíl vlastnictví jednotlivých organizací, které akcelerátory zakoupily.
Využití GPU času posuzujeme v rovině skupinových projektů (osobní projekty k výkonu GPU karet přístup nemají) a v ideálním případě každá organizace využije GPU čas adekvátně tomu, kolik GPU karet vlastní.
Využití cloudových zdrojů organizacemi
Bližší vhled do využití zdrojů zákazníků (CPU time) dle organizací.
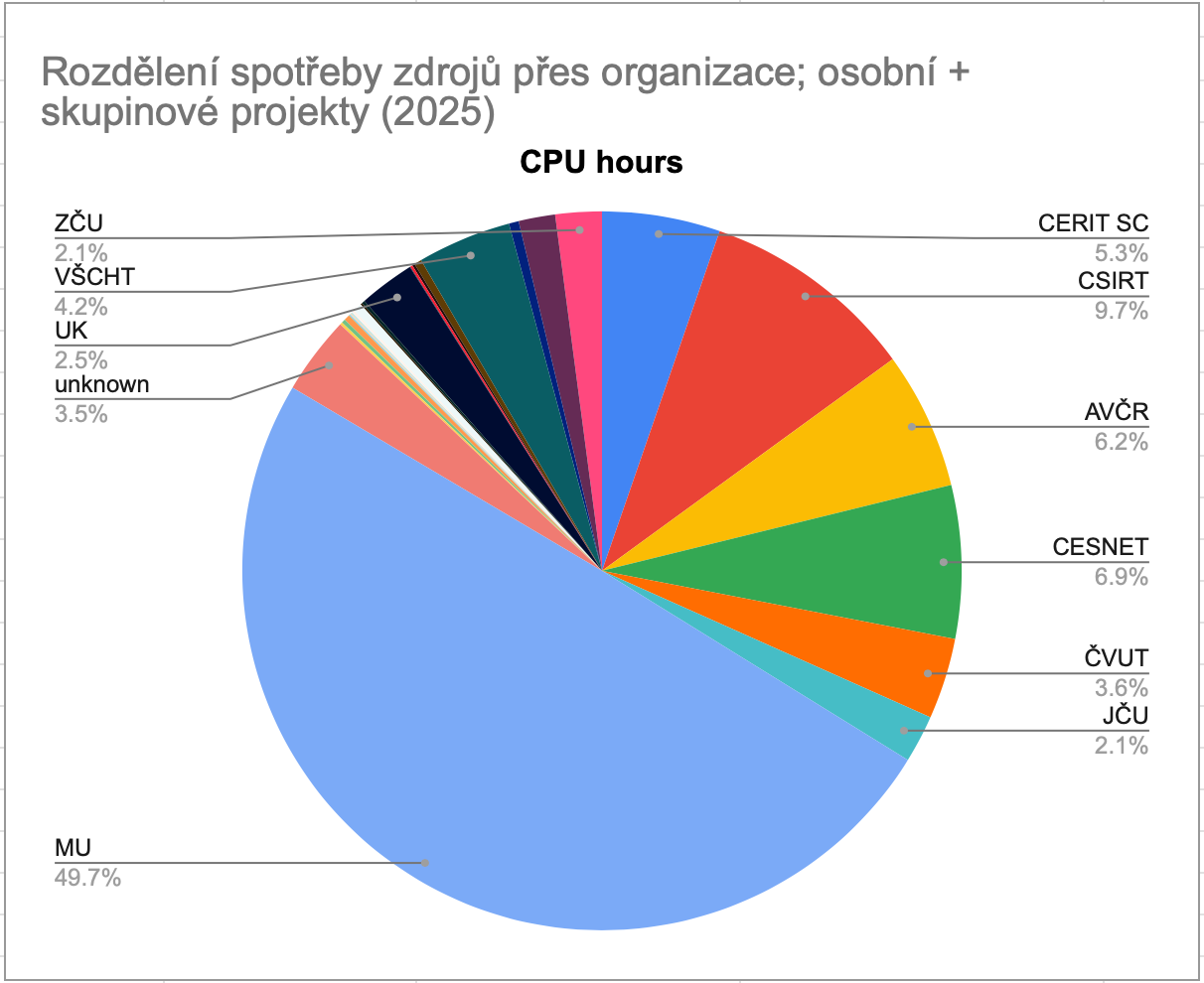
Úložné prostory
Meziročně opět vzrostlo zaplnění diskových polí v MetaCentru i v CERIT-SC. Mimo to se podařilo integrovat disková pole jiných vlastníků do infrastruktury MetaCentra (CEITEC, ELIXIR, FZÚ, TUL). Přístup na taková pole je dedikován vlastníkům, po dohodě s nimi může být přístupný i pro další uživatele.
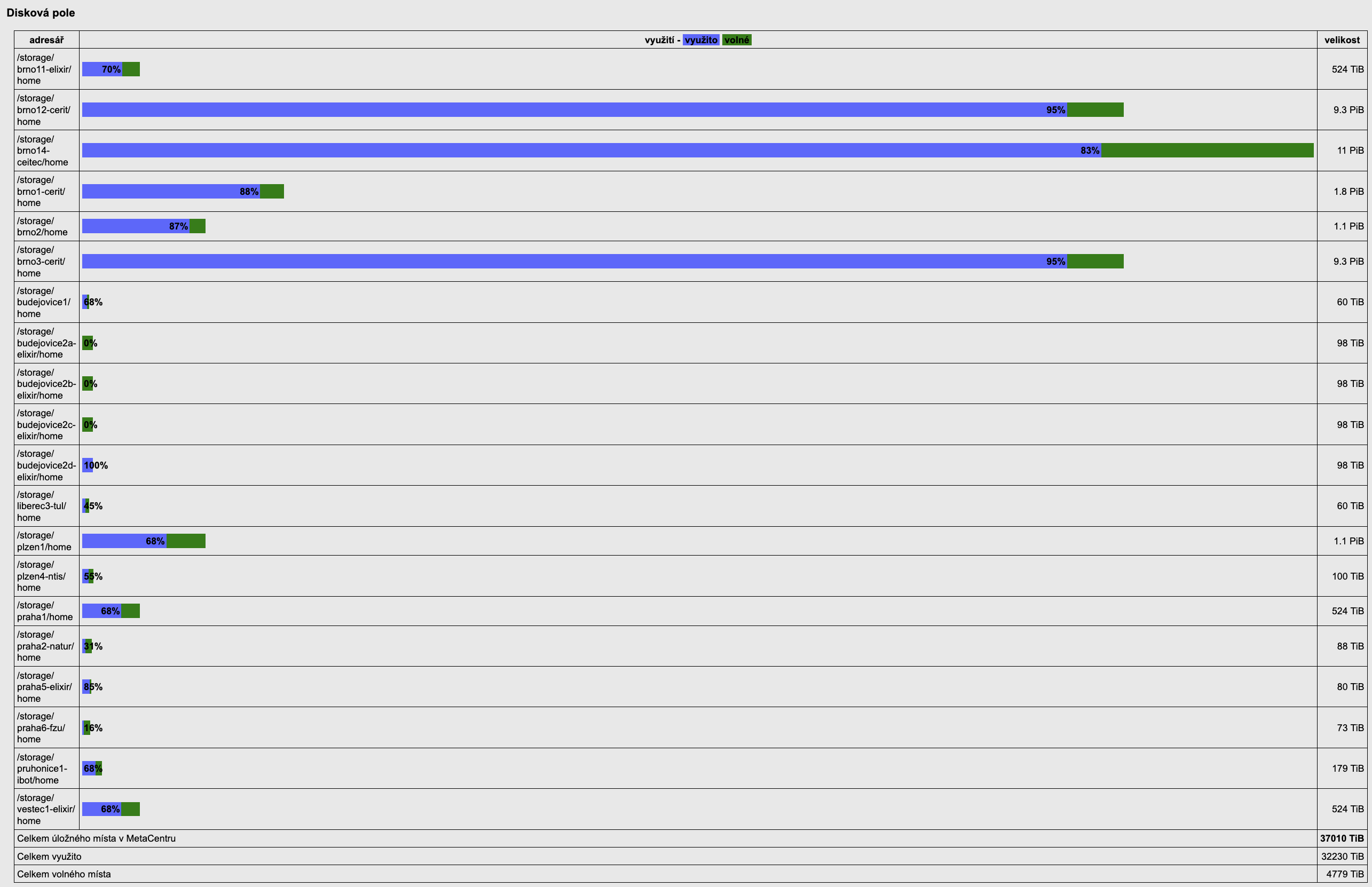
Publikace
Seznam publikací s poděkováním e-INFRA CZ infrastruktuře z WoS (502 publikací) je k dispozici v samostatném dokumentu. [PDF]
Následující grafy jsou pořízené z portálu WoS.
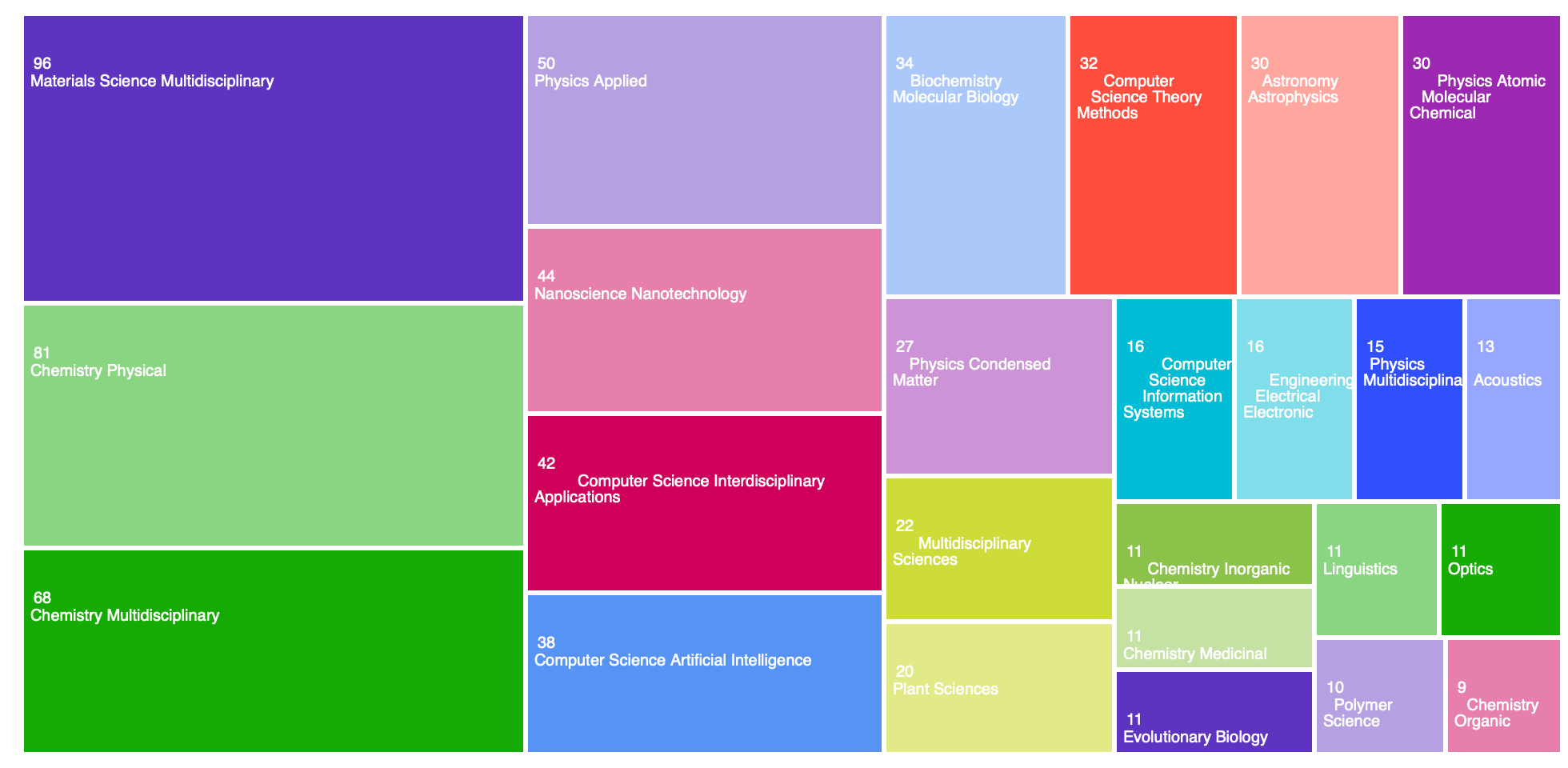
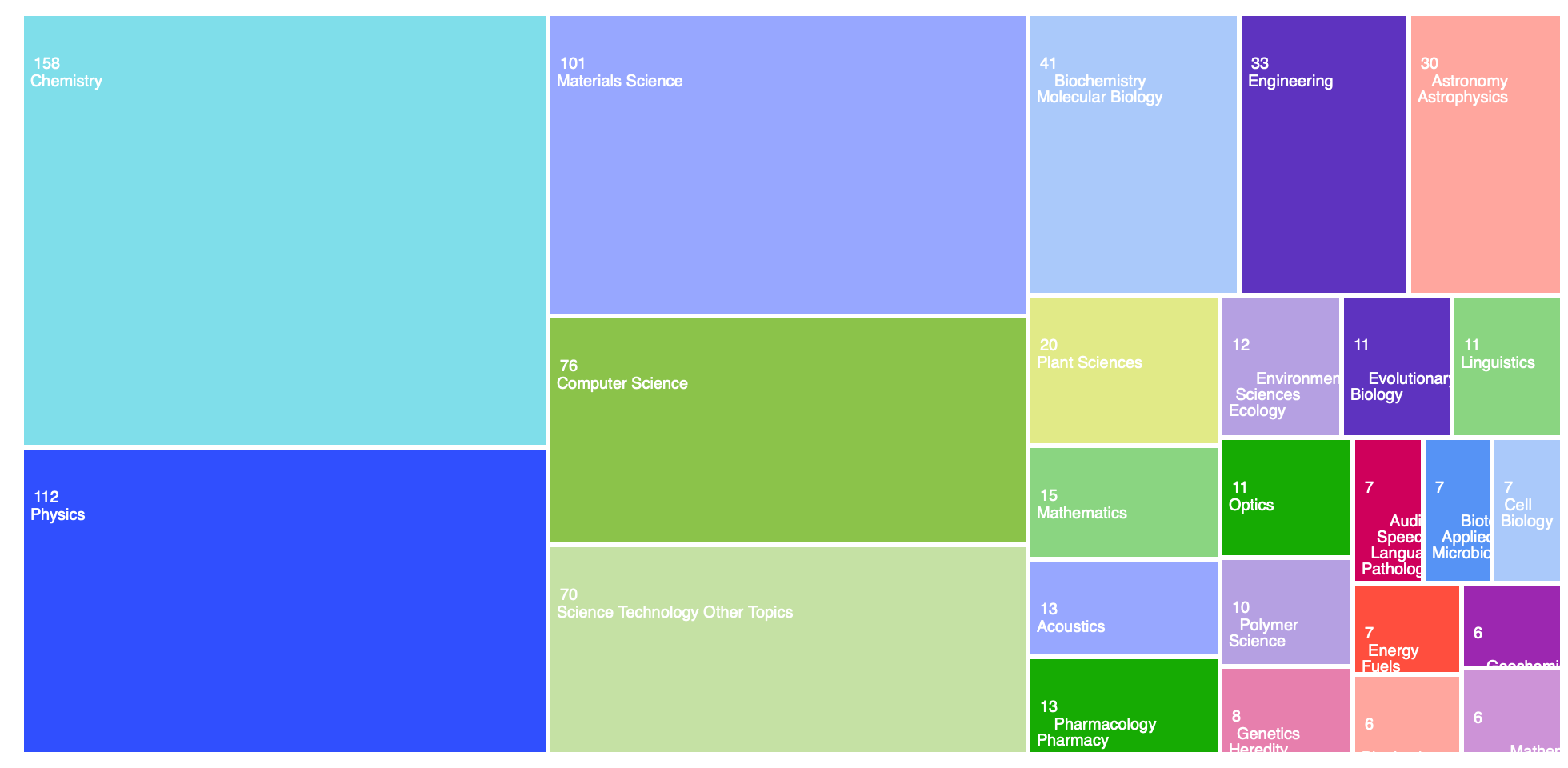
Organizace u publikací s poděkováním e-INFRA CZ (WoS)
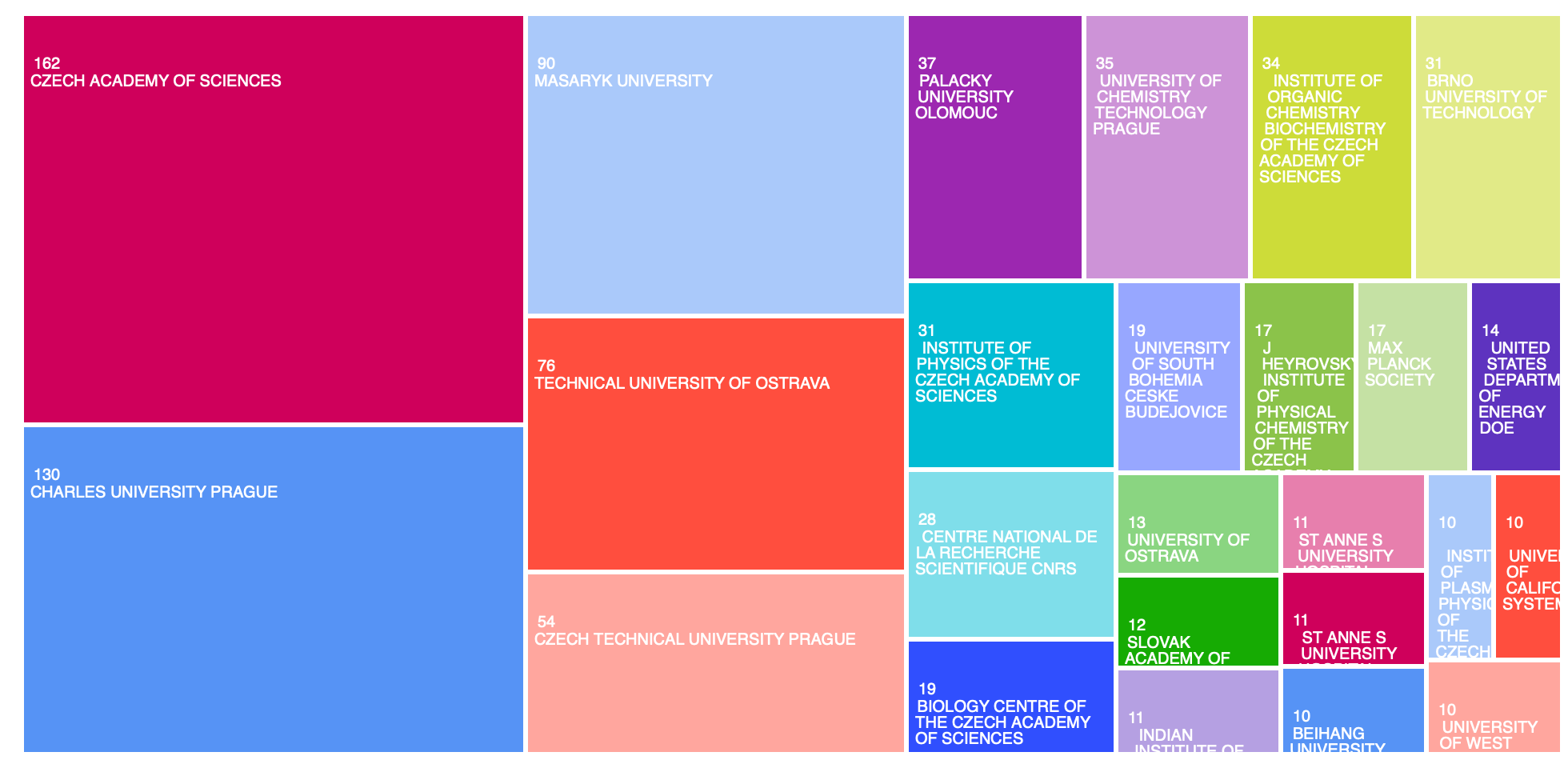
Vědní obory (WoS)
EGI statistiky
EGI HPC grid
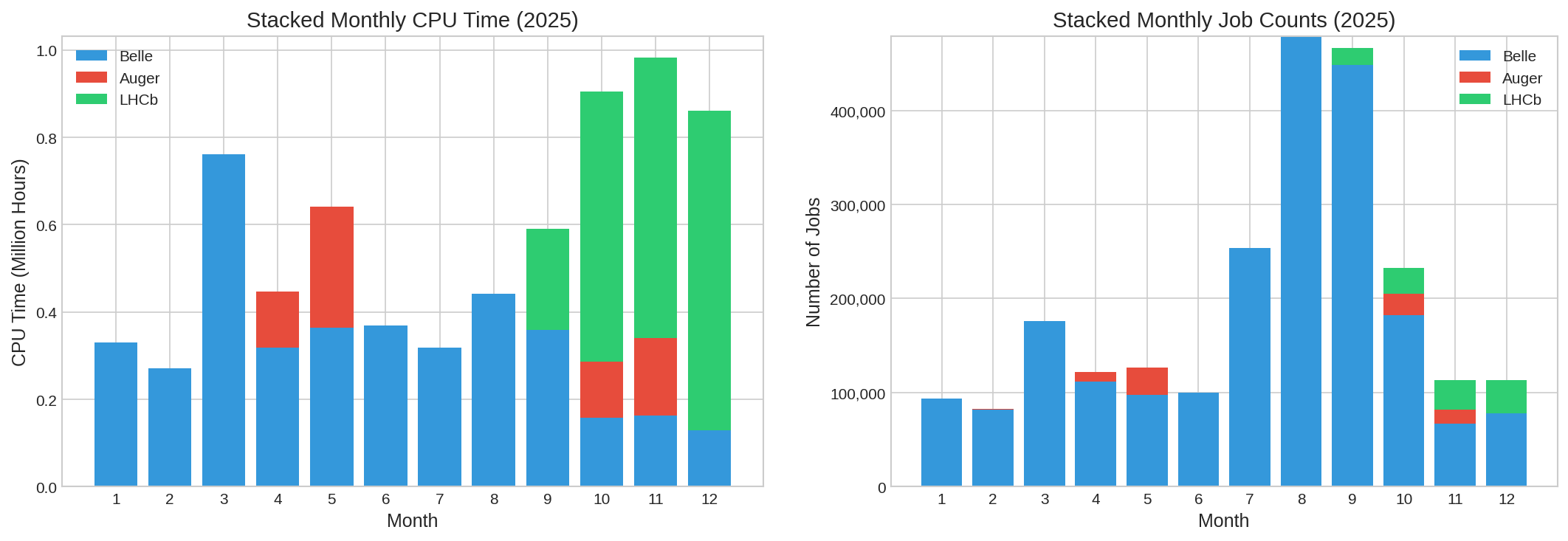
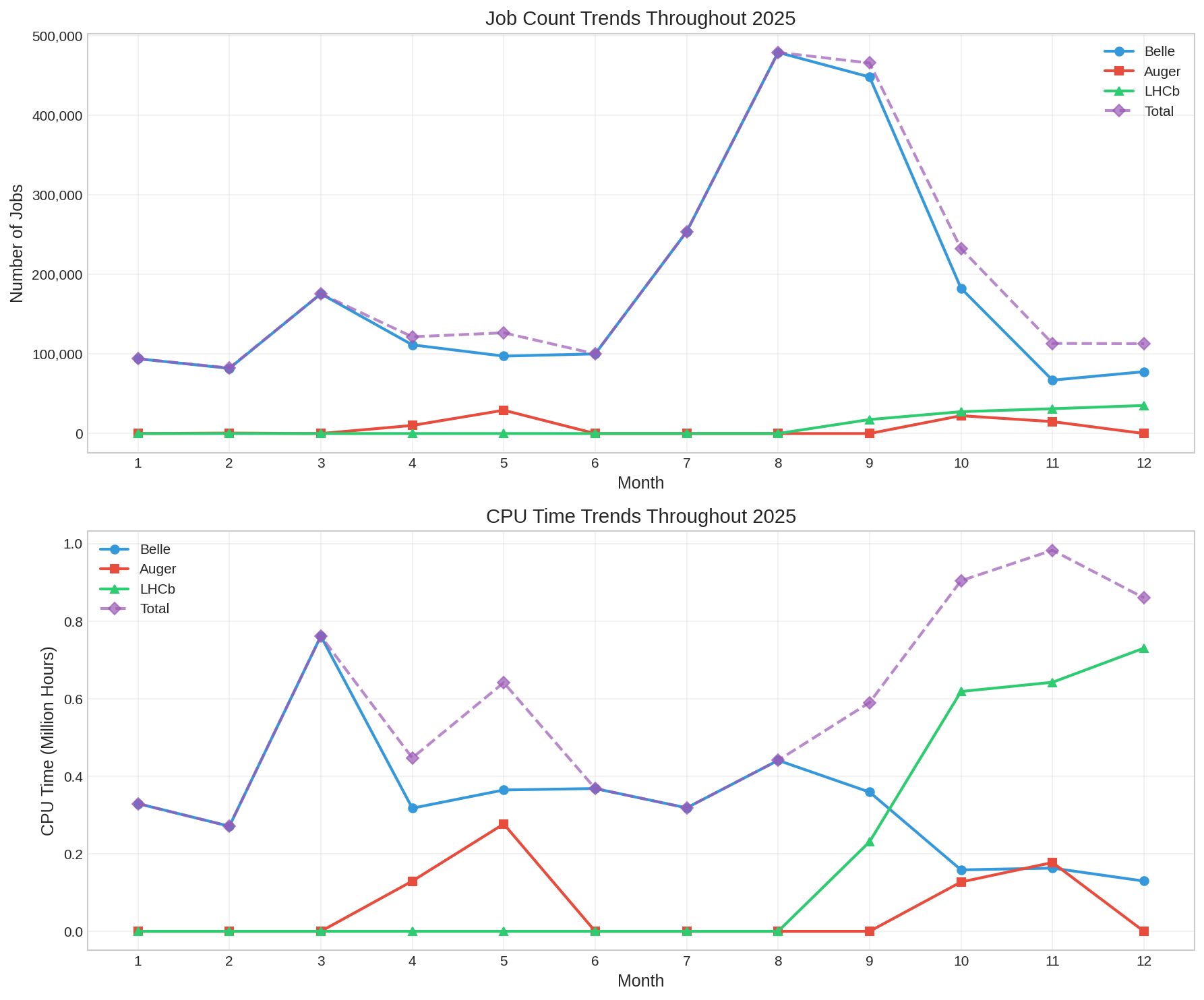
Pro mezinárodní zapojení do projektů jsme v rámci EGI vyhradili zdroje CESNETu (cluster skurut, 960 CPU) a zdroje FZÚ AV ČR (praguelcg2, 6000 CPU). V roce 2025 bylo na clusteru skurut spuštěno 2,4 milionů gridových úloh, jejich normovaný propočítaný čas činil 789 CPU let. Na praguelcg2 bylo propočítáno 8,6 milionu úloh a 5071 CPU let.
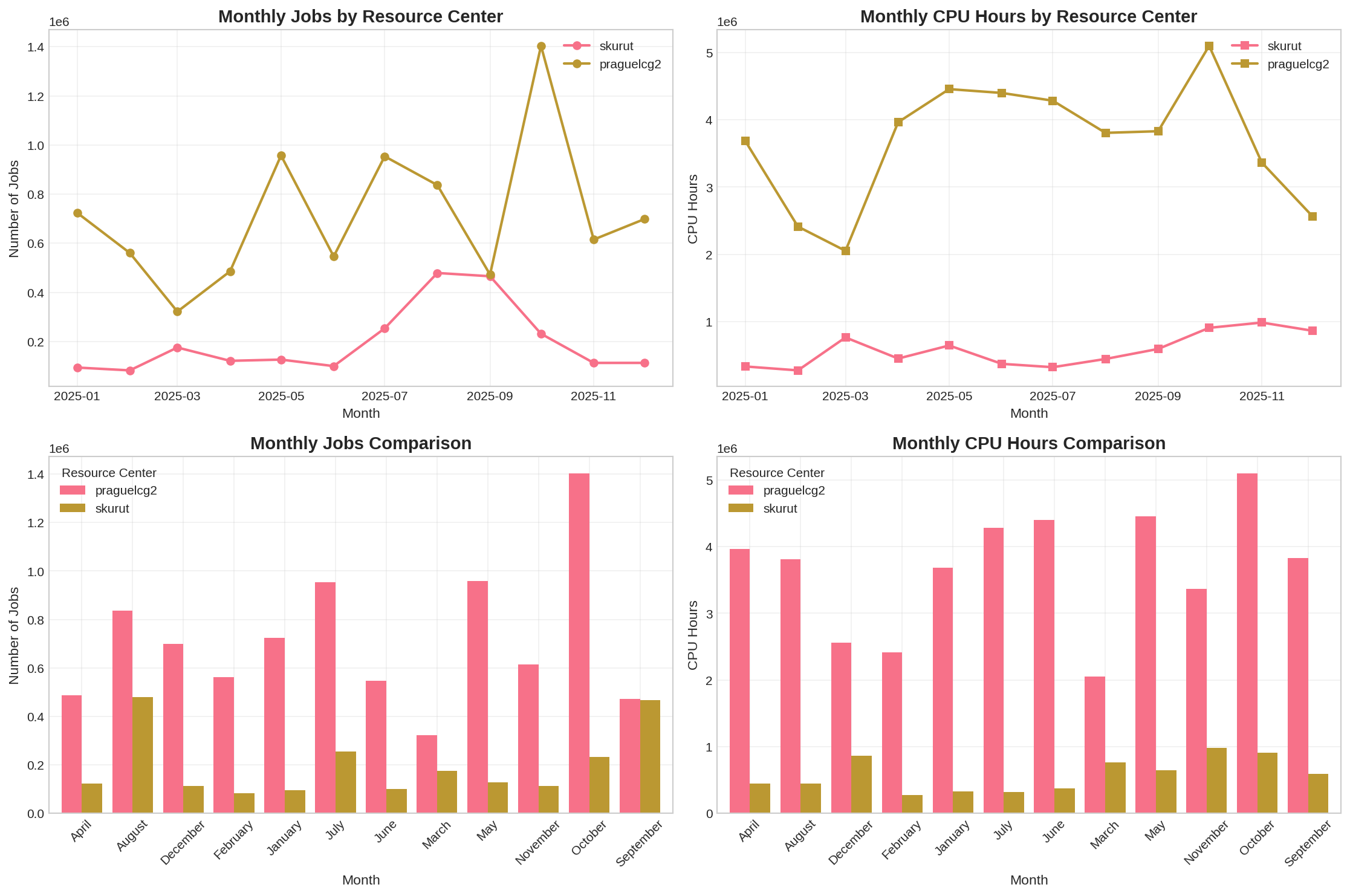
Podrobnější statistiky skurut
| VO | Total Jobs | Percentage |
|---|---|---|
| Belle | 2,169,575 | 92.0% |
| Auger | 77,456 | 3.3% |
| LHCb | 111,485 | 4.7% |
| Total | 2,358,516 |
100 |
| VO | CPU Hours | Percentage |
|---|---|---|
| Belle | 3,984,139 hrs | 62.2% |
| Auger | 711,518 hrs | 5.7% |
| LHCb | 2,223,389 hrs | 32.1% |
| Total | 6,919,078 hrs | 100% |