Statistika 2011Q1
Provozní statistiky za 1. pololetí roku 2011
1.1.2011 – 30.6.2011
Pozn.: V závorce jsou pro srovnání údaje za 1. pololetí roku 2010.
- Počet úloh: 290 tis. (280 tis.)
- Celkový propočítaný čas: 3 mil. CPU hodin (3 mil. CPU hodin)
- Počet aktivních uživatelů (s aktivním účtem v roce 2011): 410 (385)
- Počet prodloužených účtů: 295 (281)
- Počet nově založených účtů: 115 (104)
- Počet uživatelů, kteří spustili alespoň jednu úlohu: 206 (187)
- Počet uživatelů využívající datová úložiště: 269 (289)
- Počet CPU: 1800 (1500)
- Počet souborů na diskovém poli: 84 mil. (80 mil.)
- Objem dat na diskovém poli: 77 TB (60 TB)
První pololetí roku 2011 bylo v MetaCentru ve znamení přechodu z komerčního PBS Pro plánovače na plánovací systém založený na volně dostupném nástroji Torque. Tento přechod probíhal postupně, kdy jednotlivé clustery byly v průběhu času převáděny ze správy PBS Pro do správy Torque. Jedním z důsledků tohoto přechodu je i nižší celkové vytížení ve srovnání s rokem 2010.
Před každým takovým převodem bylo totiž potřeba počkat na dokončení úloh, které na daném clusteru běžely. Zároveň ale bylo nutné zabránit novým úlohám ve spouštění na daném clusteru, což logicky vedlo k nižšímu vytížení strojů ve srovnání s rokem 2010. Uživatelé se tak postupně museli rozhodnout, kdy přestoupí na nový plánovací systém. Navíc, v průběhu zavádění systému bohužel došlo v některým případech ke ztrátě některých statistických dat, což způsobilo, že pro některé stroje nebylo možno zrekonstruovat vytížení za celé období (zde prezentované vytížení je pak nižší, než ve skutečnosti bylo).
V každém případě, během relativně dlouhé doby (několik měsíců), byly clustery MetaCentra rozděleny do dvou disjunktních podmnožin a oba paralelně pracující plánovače mohly plánovat pouze nad svou podmnožinou, což pochopitelně po dobu přechodu znamenalo menší výslednou efektivitu. Dalším důvodem bylo, že zatímco v roce 2010 bylo k dispozici cca 1500 CPU v 16 clusterech nyní je to již cca 1800 CPU v 21 clusterech. Konkrétně byly v prvním pololetí 2011 vyřazeny 3 clustery (konos, perian77_86, perian87_96) a 5 nových bylo zprovozněno (perian1-10, perian11-20, perian21-40, konos1-10, konos11-37). Navíc, letos již v MetaCentru nepočítal uživatel benedikt, který v loňském roku propočítal obrovské množství CPU času (cca 260 000 úloh a cca 160 CPU roků, viz statistika z roku 2010).
Následující grafy ukazují jak se postupný přechod z PBS Pro na Torque projevoval ve využití obou systémů. Grafy zachycují absolutní a kumulativní četnosti příchodu úloh během prvního pololetí pro oba plánovače, přičemž je patrno, jak postupně Torque plně nahradil dosavadní PBS Pro.
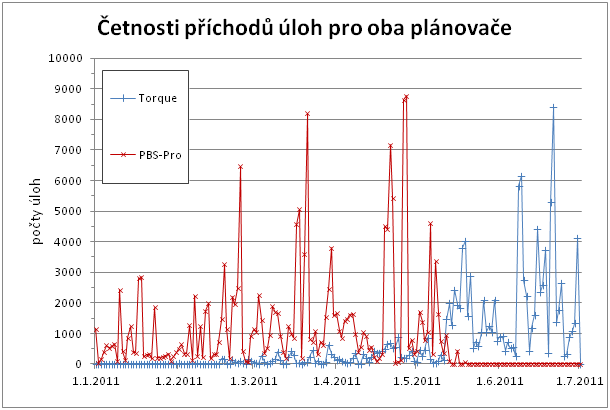
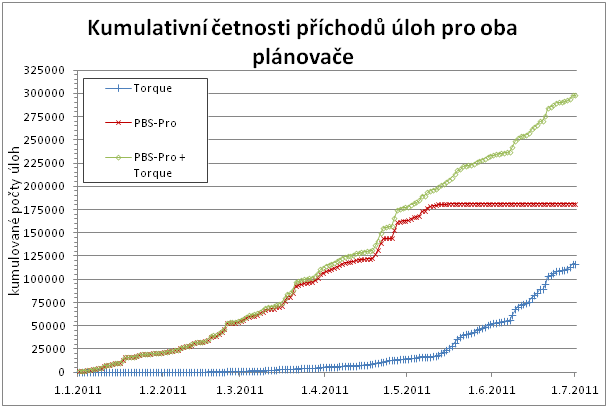
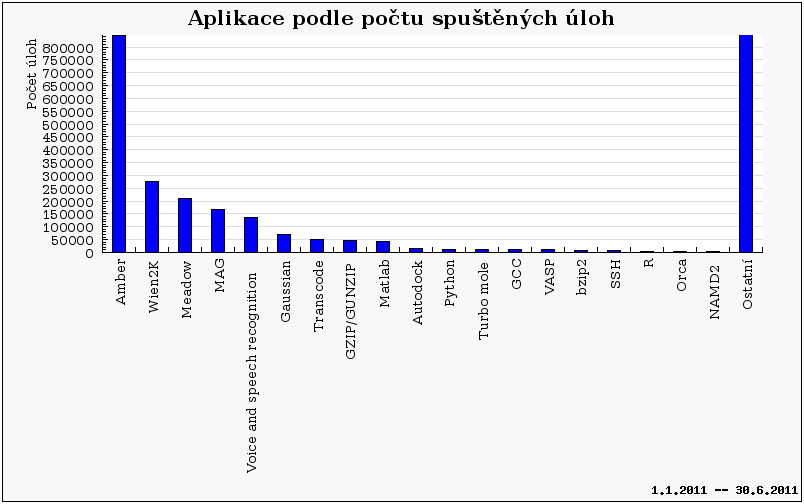
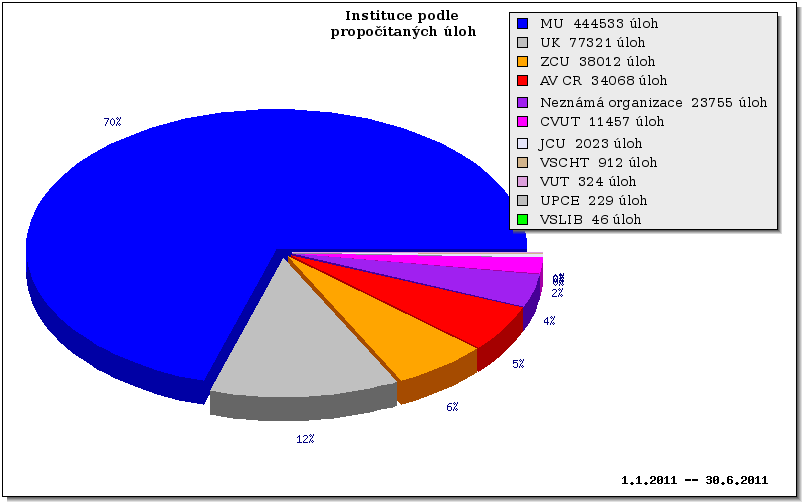
Co se týče počtu úloh, ve sledovaném období bylo dokončeno 289 986 úloh, přičemž 177 049 úloh připadá na původní PBS Pro prostředí, zatímco 112 937 úloh již pochází z prostředí Torque.
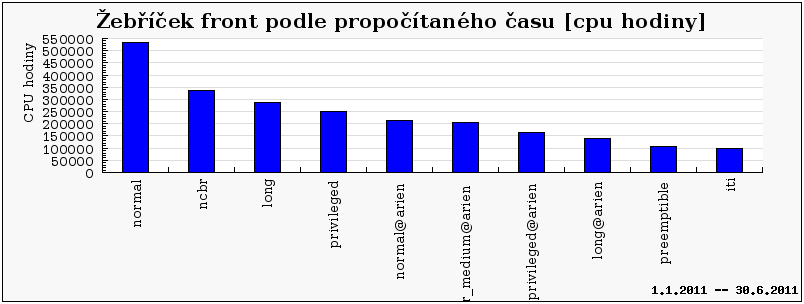
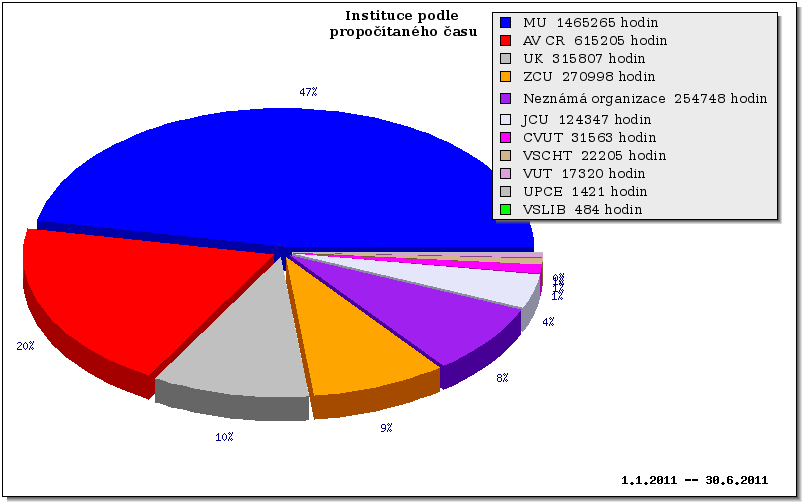
Z hlediska propočítaného času byly nejvíce vytížené fronty normal a normal@arien, kdy druhá jmenovaná značí frontu normal v prostředí Torque (Torque běží na serveru arien.ics.muni.cz).
S tímto stavem koresponduje i graf doby běhu úloh, kdy je zřejmé, že valná většina úloh běží dobu kratší než 24 hodin (24h je limit fronty normal). Je to dáno tím, že oproti minulému pololetí jsme zaznamenali úbytek dlouhých úloh, jak je patrné z následujícího grafu „Doba běhu úloh“. Jako jednoznačně pozitivní se ukazuje fakt, že výrazně ubylo extrémně krátkých úloh do 10 sekund, což svědčí o dobré spolupráci s uživateli a fungující uživatelské podpoře, neboť v této kategorii se typicky nacházejí úlohy, které skončily chybou.
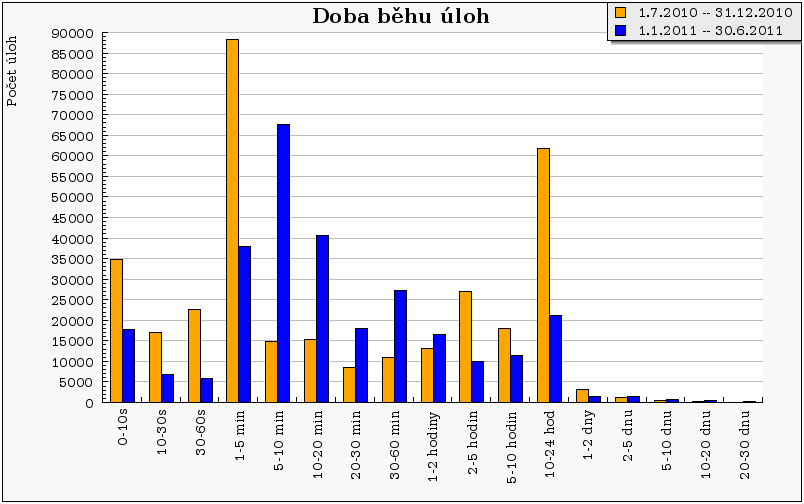
Na druhou stranu je patrné, že většina úloh běží dokonce méně než 2 hodiny (viz prvních 9 sloupců grafu). Z toho plyne, že pro tyto úlohy by spíše vyhovovala fronta short, jejíž limit je právě 2 hodiny.
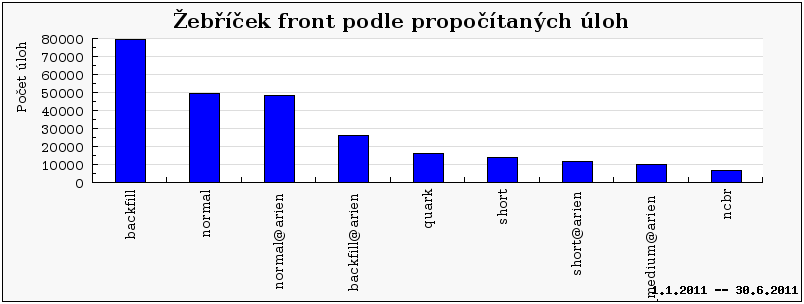
Jak ale ukazuje graf níže (viz Žebříček front podle propočítaných úloh), fronty short jsou mnohem méně populární ve srovnání s frontami backfill nebo normal. Toto je ve skutečnosti relativně špatná zpráva, neboť ukazuje, že buď nejsou uživatelé schopni rozumně aproximovat délku běhu svých úloh (což je běžný jev), anebo pro ně existující fronta short není rozumně použitelná. Tomu by nasvědčovala vysoká popularita fronty backfill (limit 24h), která umožňuje rychlé spouštění „výplňových“ jednoprocesorových úloh, které však mohou být kdykoliv ukončeny prioritnější úlohou. Jako jedno z opatření jsme na jaře roku 2011 změnili nastavení vlastností fronty short, tak že jsme zvýšili limit na počet souběžně běžících úloh v této frontě. Cílem tohoto opatření je zvýšit využití této jinak „nepopulární“ fronty.
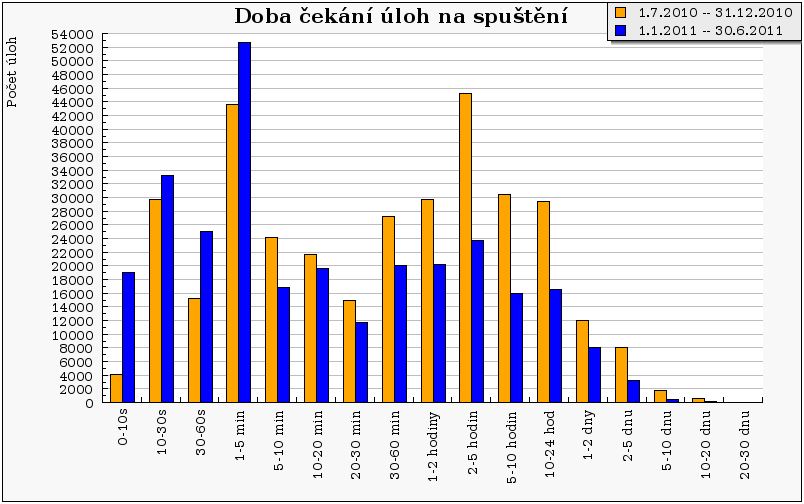
Následující graf „Doba čekání úloh na spuštění“ představuje rychlost „odezvy“ systému. Ze srovnání je patrné, že oproti minulému pololetí došlu ke zlepšení v době čekání úloh na spuštění. „Těžiště“ se posunulo více doleva, tedy došlo ke zvýšení počtu úloh, které odstarují do pěti minut od příchodu do systému. Naopak klesl počet úloh, které odstartují po době delší než 5 minut. Plných 50% úloh je nyní spuštěno během prvních 10 minut od odeslání do systému, zatímco v minulém pololetí to bylo pouze 35% úloh. Důvody tohoto chování mohou být různé, např. vyšší počet procesorů a nižší vytížení strojů ve srovnání s minulým pololetím, případně lepší nastavení nového systému Torque, který v sobě obsahuje nástroje zabraňující strádání čekajících úloh.
Další zajímavé charakteristiky
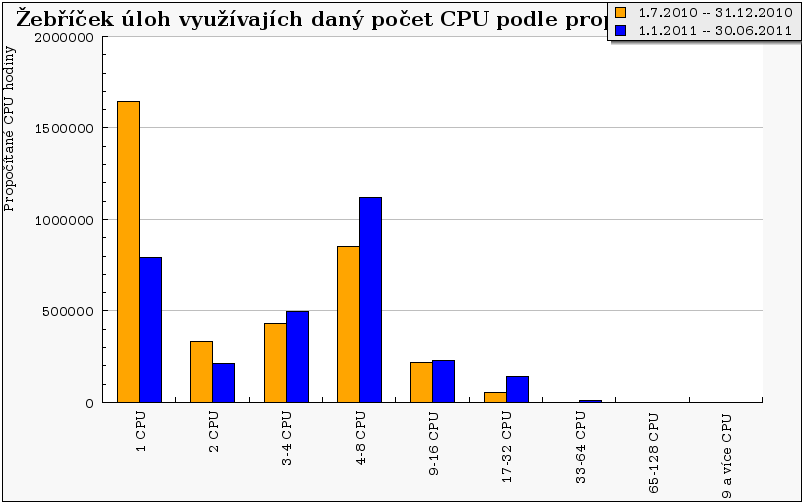
Oproti roku 2010 se výrazně změnila skladba úloh, kdy nejvyšší propočítaný čas patří paralelním úlohám o 4-8 CPU. Dále došlo k nárůstu u úloh vyžadujících 3-4 CPU, respektive 9-16 CPU a 17-32 CPU. Oproti tomu klesl počet jednoprocesorových úloh, což je jednak do jisté míry dáno tím, že už nepočítá uživatel benedikt, ale zejména tím, že uživatelská podpora věnovala velké úsilí tomu, aby naučila uživatele MetaCentra správně a efektivně paralelizovat jejich výpočty, což ve výsledku vedlo k tomu, že se zvýšila popularita víceprocesorových úloh. Navíc díky novému nastavení plánovače, kdy je zapnuta ochrana před tzv. strádáním, už víceprocesorové úlohy nemusejí čekat tak dlouho jako dříve. Negativním dopadem tohoto nastavení je však nižší průměrné vytížení strojů, neboť plánovač dopředu postupně rezervuje procesory potřebné pro danou víceprocesorovou úlohu a ty pak po jistou dobu nemohou být vytíženy.
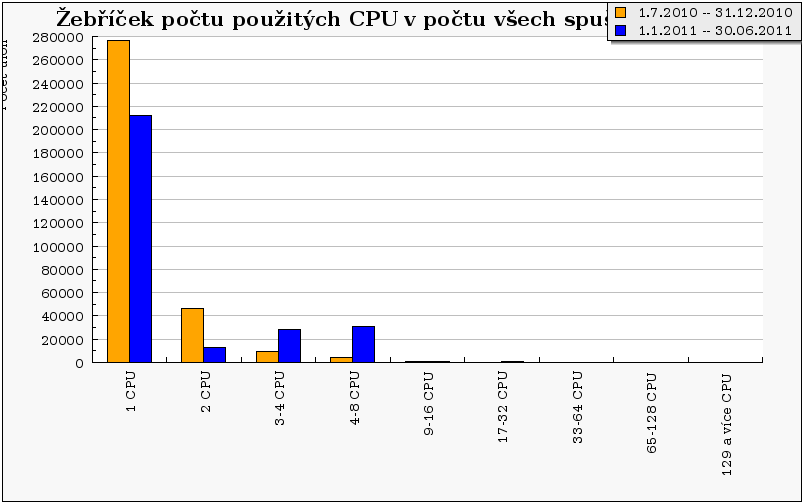
Obdobný trend jako na předchozím grafu je patrný i na následujícím grafu, který zobrazuje počty úloh vzhledem k použitým CPU. Zde opět oproti roku 2010 pozorujeme nárůst počtu úloh co požadují 3 a více CPU na úkor 1 a 2 CPU úloh.
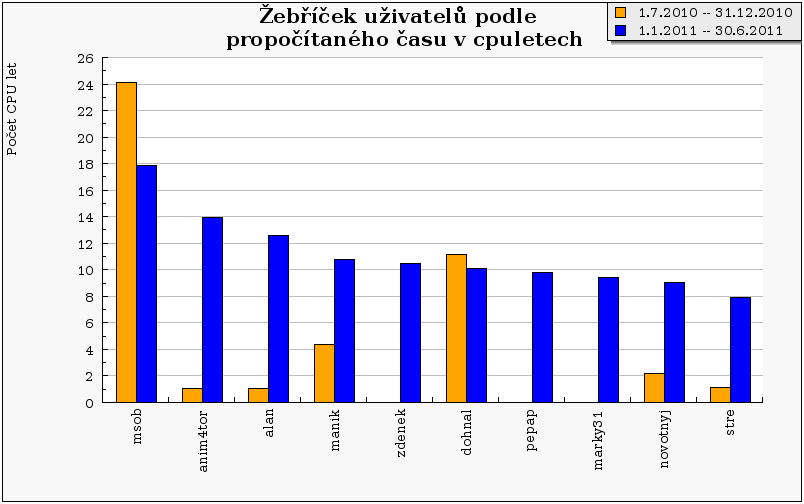
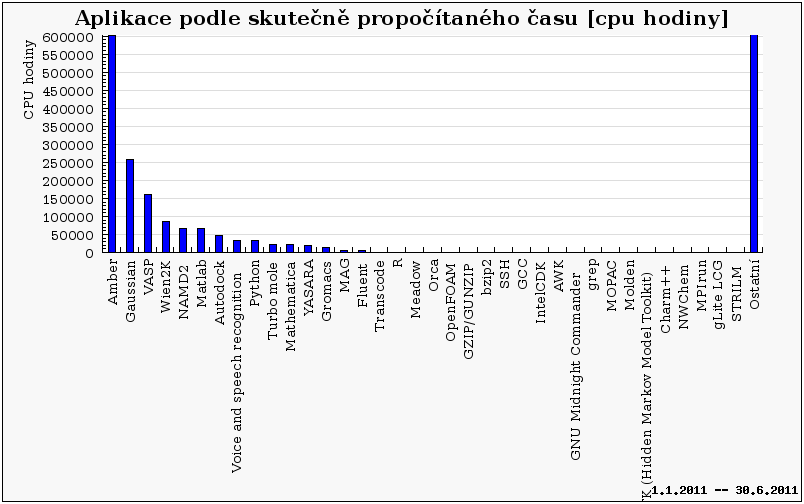
Následující graf ukazuje celkový propočítaný čas deseti nejaktivnějších uživatelů. Je patrné, že až na dvě výjimky všichni oproti minulému pololetí výrazně navýšili svůj propočítaný CPU čas.
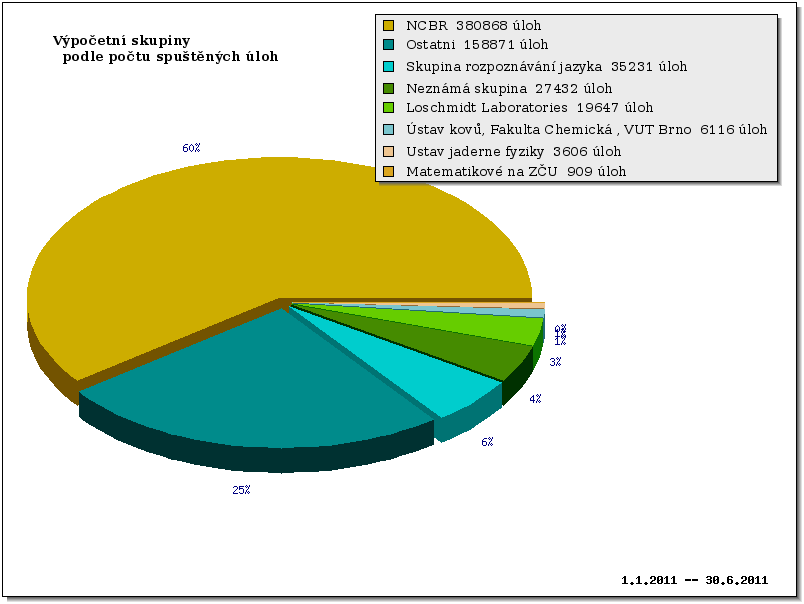
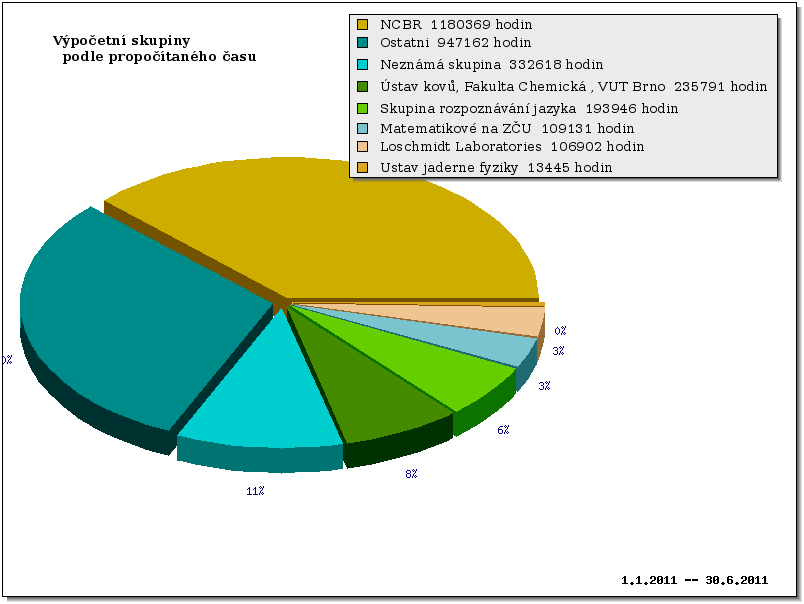
Vytížení strojů a clusterů
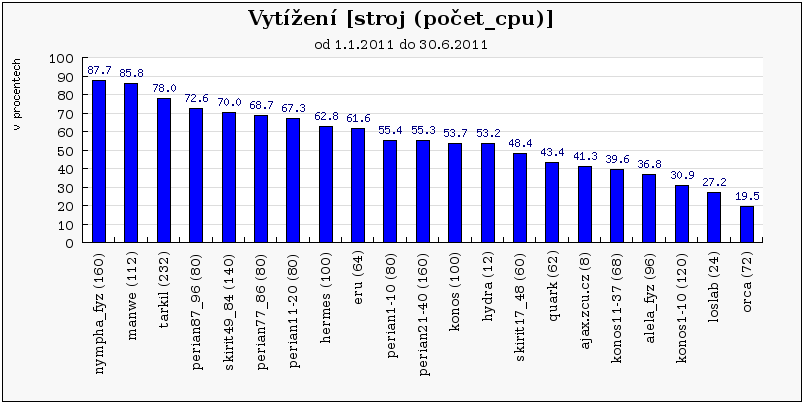
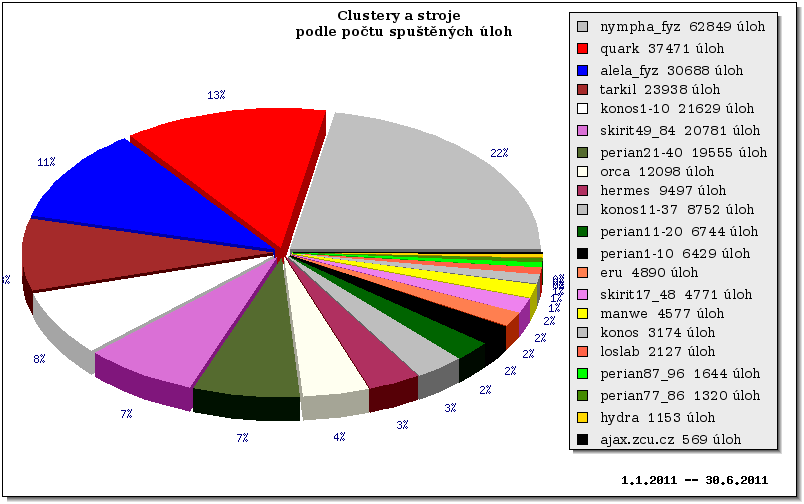
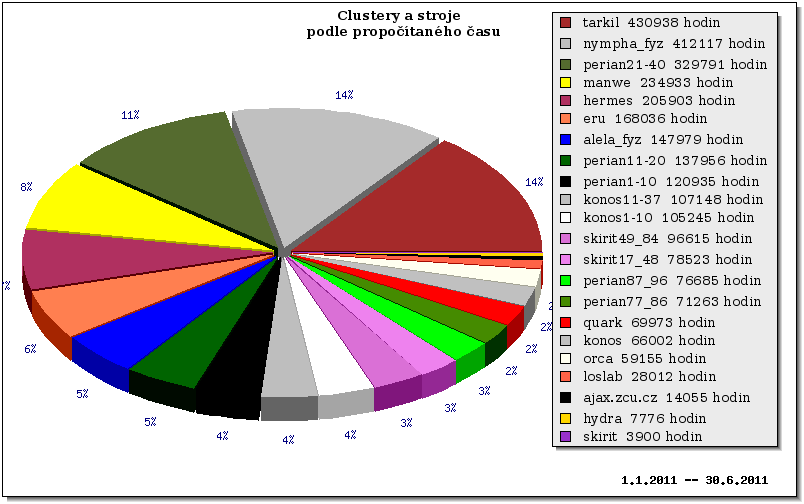
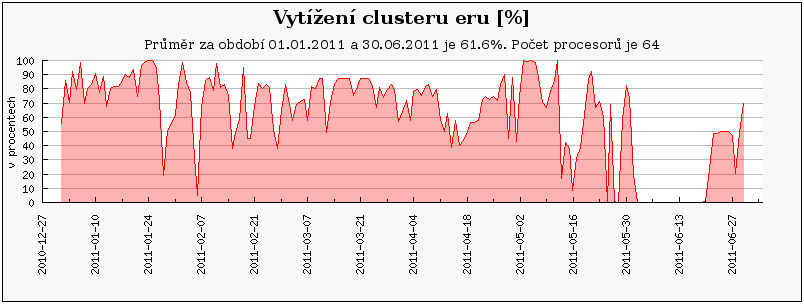
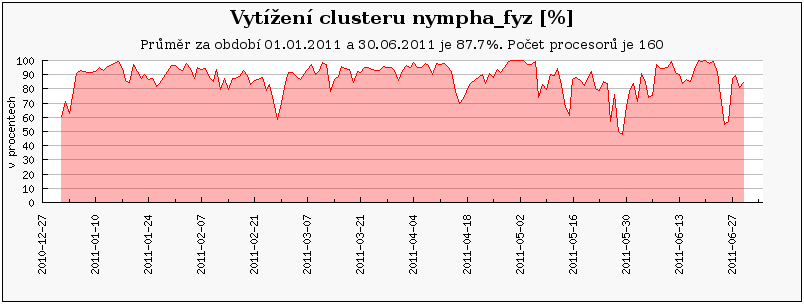
Následující grafy ukazují vytížení všech clusterů/strojů v MetaCentru za první pololetí roku 2011. Grafy jsou rozděleny do 3 skupin – nejprve jsou ukázány grafy pro clustery/stroje, které byly v provozu po celé první pololetí. Pak následují grafy vytížení pro nově přidané clustery a nakonec je ukázáno vytížení pro vyřazené clustery.
Clustery provozované v celém období
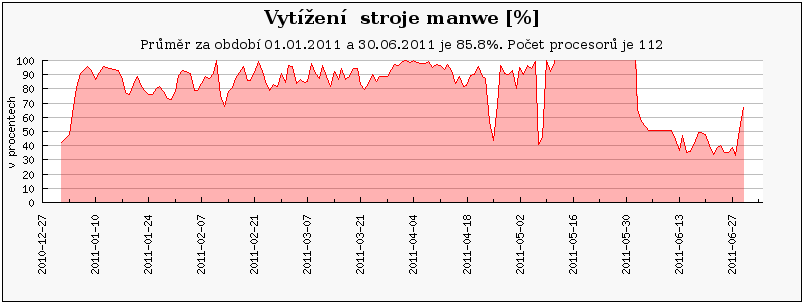
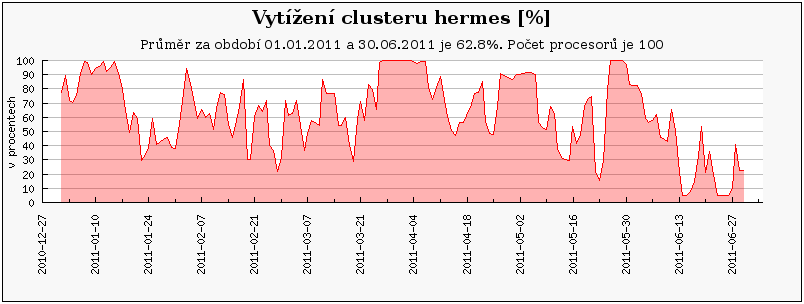
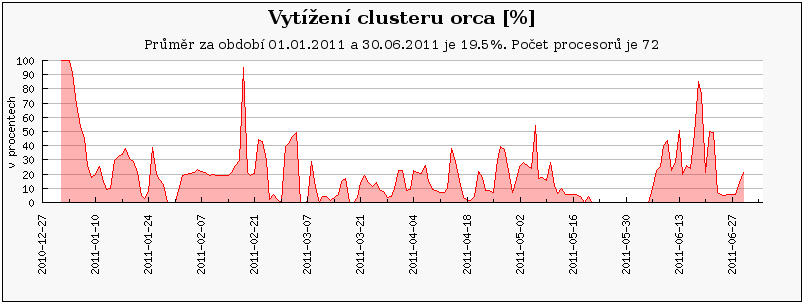
Cluster orca je primárně využíván uživateli z NCBR, kteří zde mají prioritní přístup. Ostatní zájemci z MetaCentra mohou cluster využívat prostřednictvím fronty 'preemptible', která je obdobou fronty 'long', ale úlohy v ní mohou být pozdrženy až 30 dní. Vybraní uživatelé z NCBR mohou posílat úlohy do fronty 'orca', která pozdrží úlohy běžící z fronty 'preemptible' a spustí svoje úlohy ihned. To pravděpodobně způsobilo relativně malou oblíbenost tohoto clusteru a tím pádem i nízké vytížení.
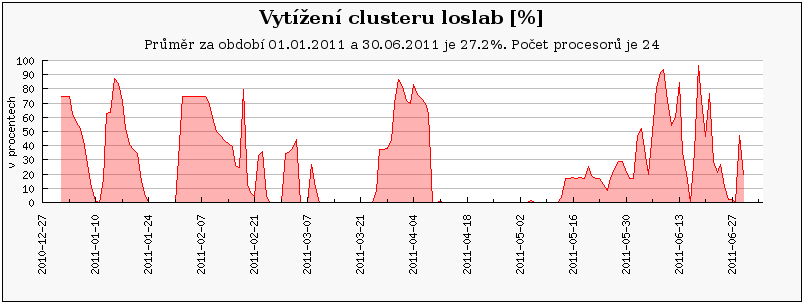
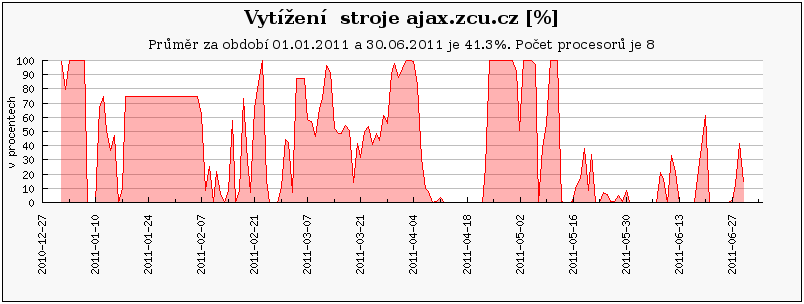
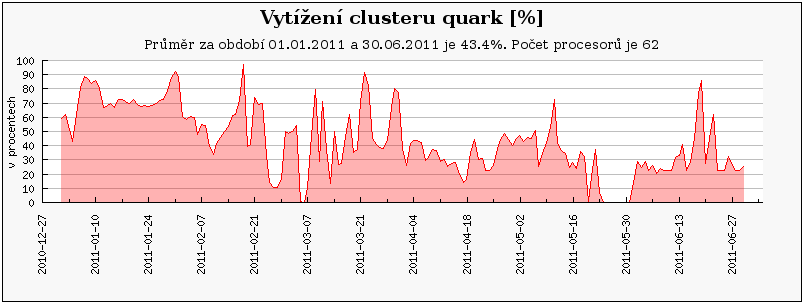
Podobně jako orca, jsou i následující clustery a stroje (loslab, ajax.zcu.cz, quark) primárně vyhrazeny vlastníkům, a proto na nich zaznamenáváme výrazně nižší vytížení než u volně přístupných clusterů.
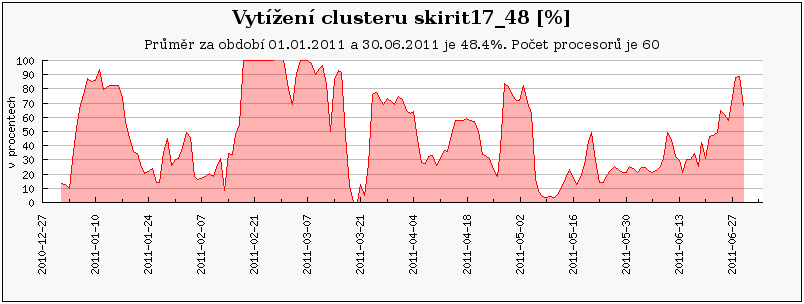
Cluster skirit17_48 je poslední 32-bit cluster, obsahující velmi slabé stroje s malou pamětí o které logicky není mezi uživateli příliš velký zájem, jak ukazuje následující graf.
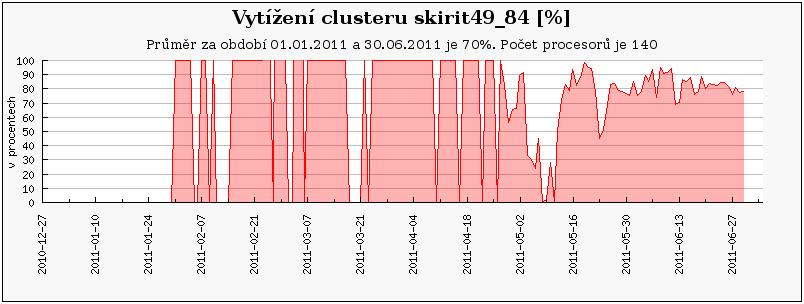
Cluster skirit49_84 byl od prosince 2010 prvním clusterem pod správou nového plánovače Torque, v té době ještě v silně experimentální verzi. Z tohoto období (prosinec – leden) se bohužel nepodařilo sebrat statistická data, což negativně ovlivnilo průměrné vytížení. Pokud bychom uvažovali až období kdy máme k dispozici veškerá data (1.2. - 30.6. 2011), stouplo by průměrné vytížení na 83,8%.
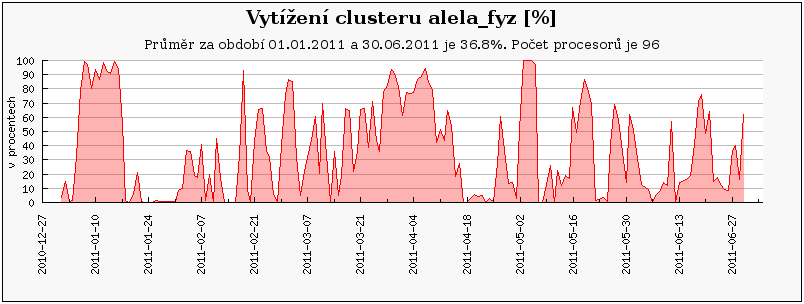
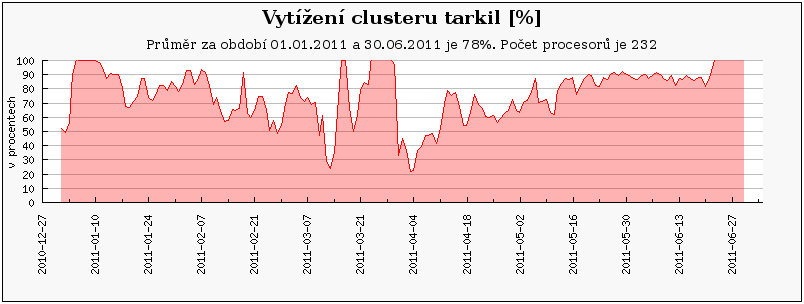
Clustery přidané v průběhu prvního pololetí 2011
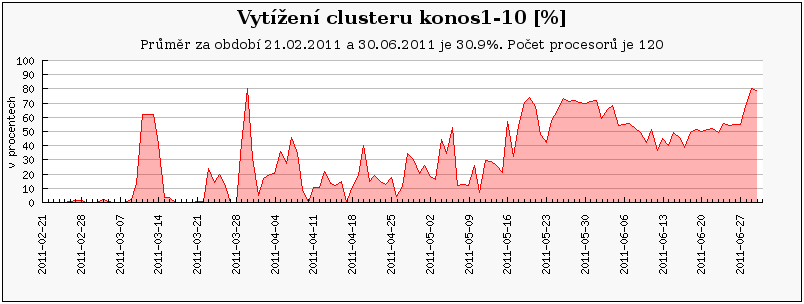
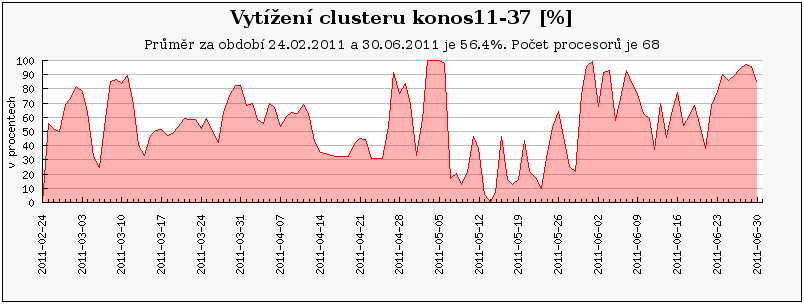
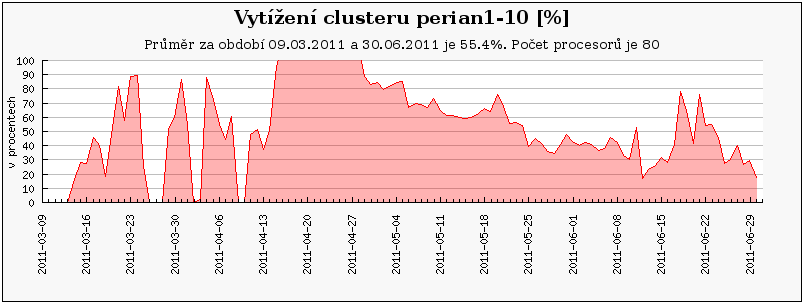
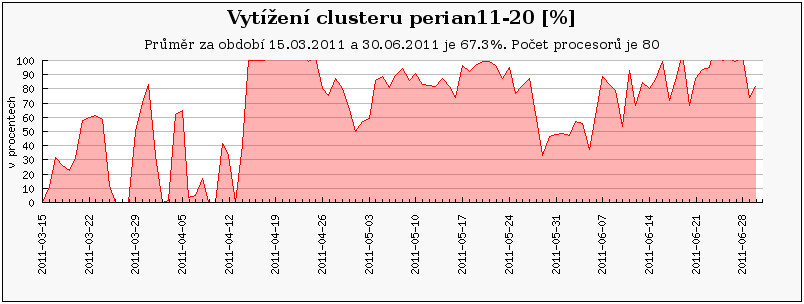
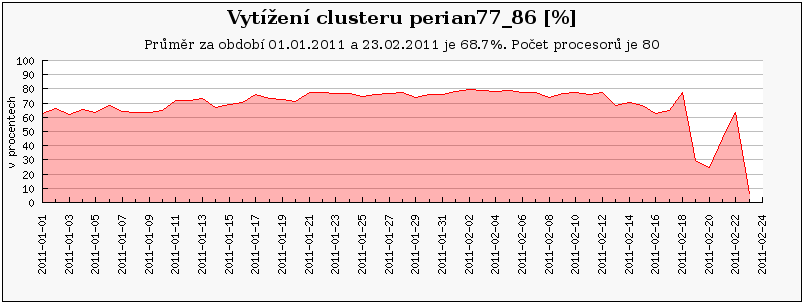
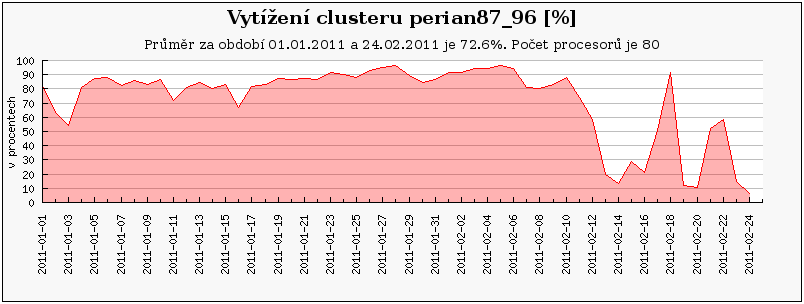
Cluster perian 21-40 jsou nově zapojené uzly, zatímco perian11-20 je přejmenovaný původní perian87_96 a perian1-10 je původní perian77_86.
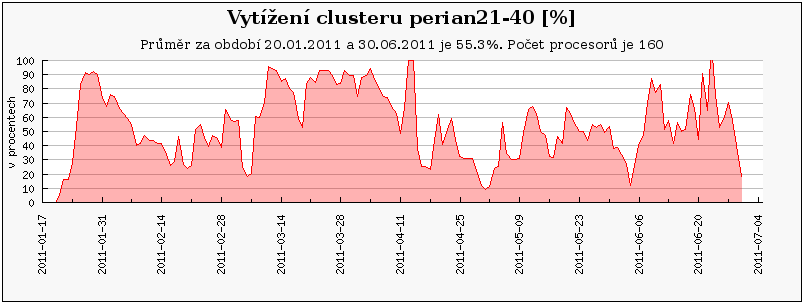
Clustery odebrané v průběhu prvního pololetí 2011
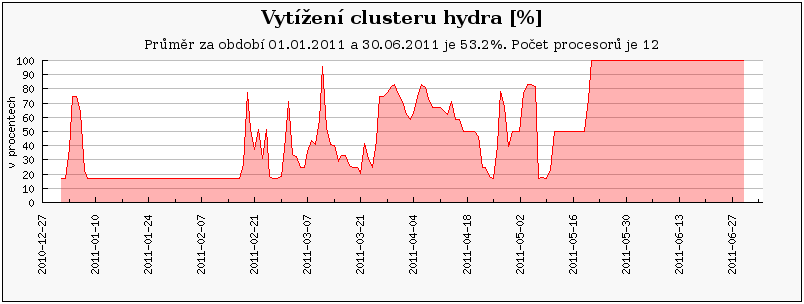
Cluster hydra je experimentální externí cluster katedry informatiky ZČU, který není spravován administrátory MetaCentra. Z tohoto důvodu je již od půlky května 2011 mimo provoz (všechny uzly jsou ve výpadku), neboť správci dosud přes urgence nenainstalovali rozhranní pro nový plánovací systém Torque.
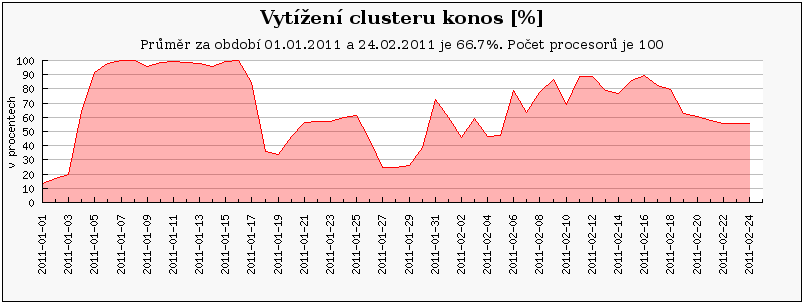
Cluster konos se na konci února přejmenovával. Z uzlů 1-10 vznikl samostaný cluster. Na těchto uzlech proběhl zároveň upgrade HW, kdy byly místo starých strojů (konos1-14) pořízeny nové stroje s následující specifikací: 2x6core Intel Xeon X5680 @ 3,33GHz, 24GB RAM. Dále vznikl samostatný stroj konos1 určený k experimentům s výpočty na GPU. Pro tento účel byl vybaven vhodnou GPU kartou.
Obdobný případ představuje cluster perian, který se taktéž na konci února přejmenovával. Nyní se perian77_86 jmenuje perian1-10 a clusteru perian87_96 nyní odpovídá perian11-20.